MERFISH whole brain spatial transcriptomics (part 2b)#
We can continue to explore our examples looking at the expression of canonical neurotransmitter transporter genes and gene Tac2 over the whole brain.
You need to be connected to the internet to run this notebook and have run through the getting started notebook.
import pandas as pd
from pathlib import Path
import numpy as np
import anndata
import matplotlib.pyplot as plt
from abc_atlas_access.abc_atlas_cache.abc_project_cache import AbcProjectCache
%matplotlib inline
We will interact with the data using the AbcProjectCache. This cache object tracks which data has been downloaded and serves the path to the requsted data on disk. For metadata, the cache can also directly serve a up a Pandas Dataframe. See the getting_started notebook for more details on using the cache including installing it if it has not already been.
Change the download_base variable to where you have downloaded the data in your system.
download_base = Path('../../data/abc_atlas')
abc_cache = AbcProjectCache.from_cache_dir(download_base)
abc_cache.current_manifest
'releases/20250531/manifest.json'
Read in the expanded cell metadata table that was created by the code in part 1.
cell = abc_cache.get_metadata_dataframe(
directory='MERFISH-C57BL6J-638850',
file_name='cell_metadata_with_cluster_annotation',
dtype={"cell_label": str,
"neurotransmitter": str}
)
cell.set_index('cell_label', inplace=True)
Read in the gene expression dataframe we created in part 2a.
exp = abc_cache.get_metadata_dataframe(
directory='MERFISH-C57BL6J-638850',
file_name='example_genes_all_cells_expression',
dtype={"cell_label": str}
)
exp.set_index('cell_label', inplace=True)
example_genes_all_cells_expression.csv: 100%|██████████| 360M/360M [03:09<00:00, 1.90MMB/s]
We define a helper functions aggregate_by_metadata to compute the average expression for a given catergory.
def aggregate_by_metadata(df, gnames, value, sort=False) :
grouped = df.groupby(value)[gnames].mean()
if sort :
grouped = grouped.sort_values(by=gnames[0], ascending=False)
return grouped
Expression of canonical neurotransmitter transporter genes#
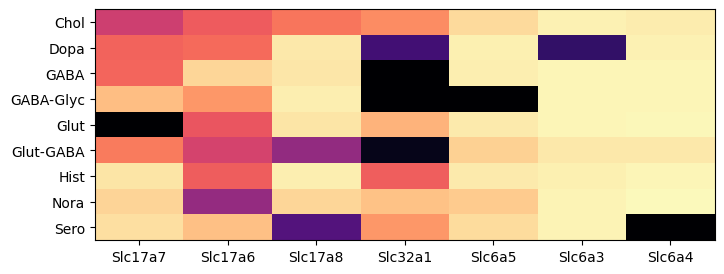
During analysis, clusters were assigned neurotransmitter identities based on the expression of of canonical neurotransmitter transporter genes. In this example, we create a dataframe comprising of expression of the 9 solute carrier family genes for all the cells in the dataset. We then group the cells by the assigned neurotransmitter class and compute the mean expression for each group and visualized as a colorized table.
The results are similar that in part 1. Using data from the whole brain, gene Slc17a7 is now most enriched in glutamatergic assigned cells. Gene Slc17a6 is most enriched in noradrenergic, then cholinergic types. Genes Slc6a5, Slc6a3 and Slc6a4 shows high specificity to glycinergic, dopaminergic, serotonergic respectively.
def plot_heatmap(df, fig_width = 8, fig_height = 4, cmap = plt.cm.magma_r, vmin = 0, vmax = 5):
arr = df.to_numpy()
fig, ax = plt.subplots()
fig.set_size_inches(fig_width,fig_height)
res = ax.imshow(arr, cmap=cmap, aspect='auto', vmin=vmin, vmax=vmax)
xlabs = df.columns.values
ylabs = df.index.values
ax.set_xticks(range(len(xlabs)))
ax.set_xticklabels(xlabs)
ax.set_yticks(range(len(ylabs)))
res = ax.set_yticklabels(ylabs)
ntgenes = ['Slc17a7', 'Slc17a6', 'Slc17a8', 'Slc32a1', 'Slc6a5', 'Slc6a3', 'Slc6a4']
filtered = exp[ntgenes]
joined = cell.join(filtered)
agg = aggregate_by_metadata(joined, ntgenes, 'neurotransmitter')
agg = agg[ntgenes]
plot_heatmap(agg, 8, 3, vmax=4)
plt.show()
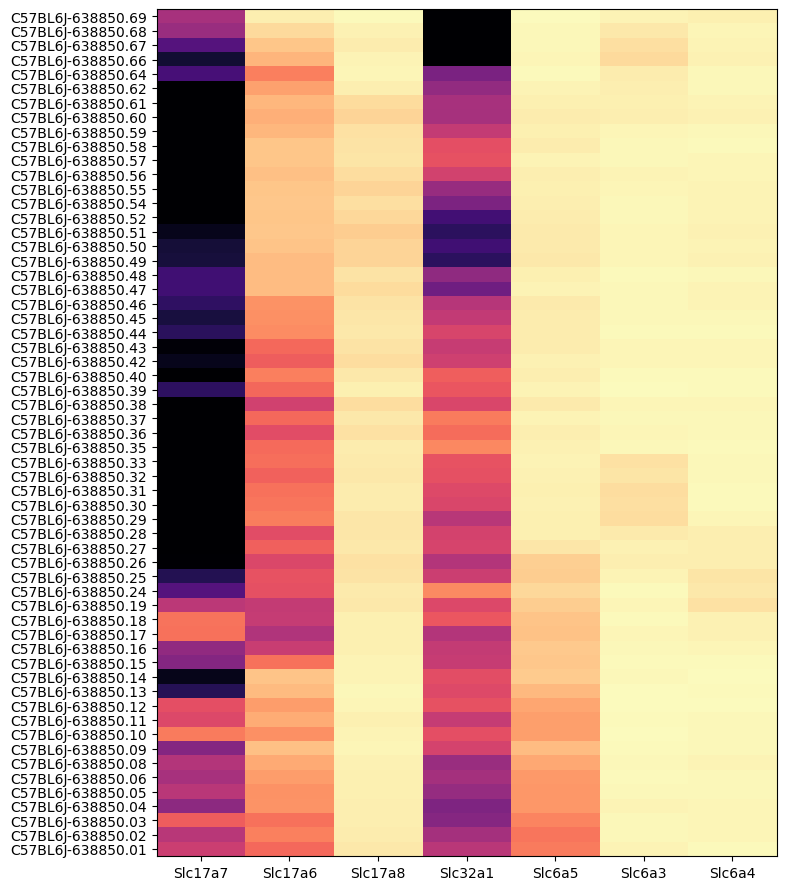
Grouping expression by dissection region of interest shows that each of these genes have distinct spatial patterns. The MERFISH data allows us to visualize these patterns in anatomical context.
agg = aggregate_by_metadata(joined, ntgenes, 'brain_section_label')
agg = agg.loc[list(reversed(list(agg.index)))]
plot_heatmap(agg, 8, 11, vmax=3)
plt.show()
We define a small helper function plot sections to visualize the cells for a specified set of brain sections either by colorized metadata or gene expression.
def plot_sections(df, feature, blist, cmap = None, fig_width = 20, fig_height = 5) :
fig, ax = plt.subplots(1,len(blist))
fig.set_size_inches(fig_width, fig_height)
for idx,bsl in enumerate(blist):
filtered = df[df['brain_section_label'] == bsl]
xx = filtered['x']
yy = filtered['y']
vv = filtered[feature]
if cmap is not None :
ax[idx].scatter(xx, yy, s=1.0, c=vv, marker='.', cmap=cmap)
else :
ax[idx].scatter(xx, yy, s=1.0, color=vv, marker=".")
ax[idx].axis('equal')
ax[idx].set_xlim(0, 11)
ax[idx].set_ylim(11, 0)
ax[idx].set_xticks([])
ax[idx].set_yticks([])
ax[idx].set_title("%s" % (bsl))
plt.subplots_adjust(wspace=0.01, hspace=0.01)
return fig, ax
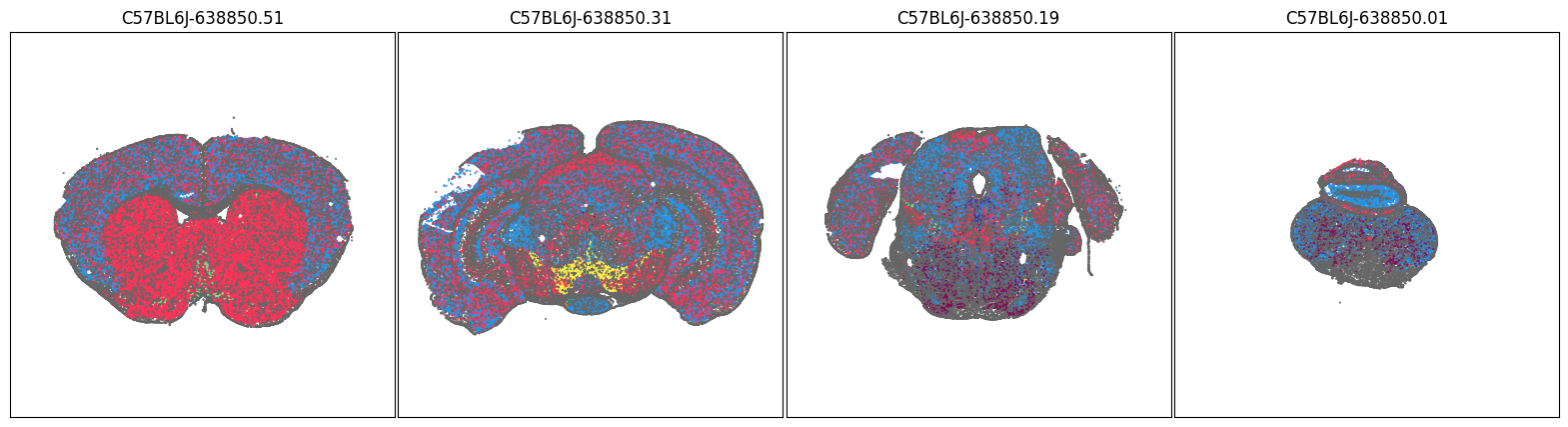
We will use the aggregate by brain section table above to pick a four sections of interest and plot cells in those sections by neurotransmitter type and by each of the transporter genes.
blist = ['C57BL6J-638850.51', 'C57BL6J-638850.31', 'C57BL6J-638850.19', 'C57BL6J-638850.01']
fig, ax = plot_sections(joined, 'neurotransmitter_color', blist, cmap=None)
plt.show()
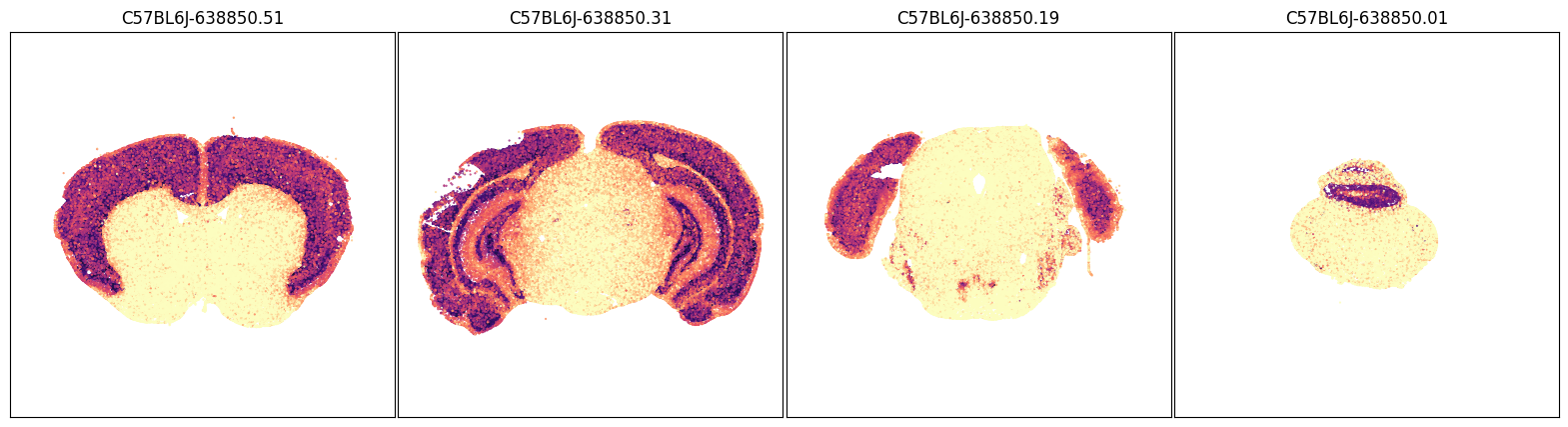
fig, ax = plot_sections(joined, 'Slc17a7', blist, cmap=plt.cm.magma_r)
plt.show()
fig, ax = plot_sections(joined, 'Slc17a6', blist, cmap=plt.cm.magma_r)
plt.show()
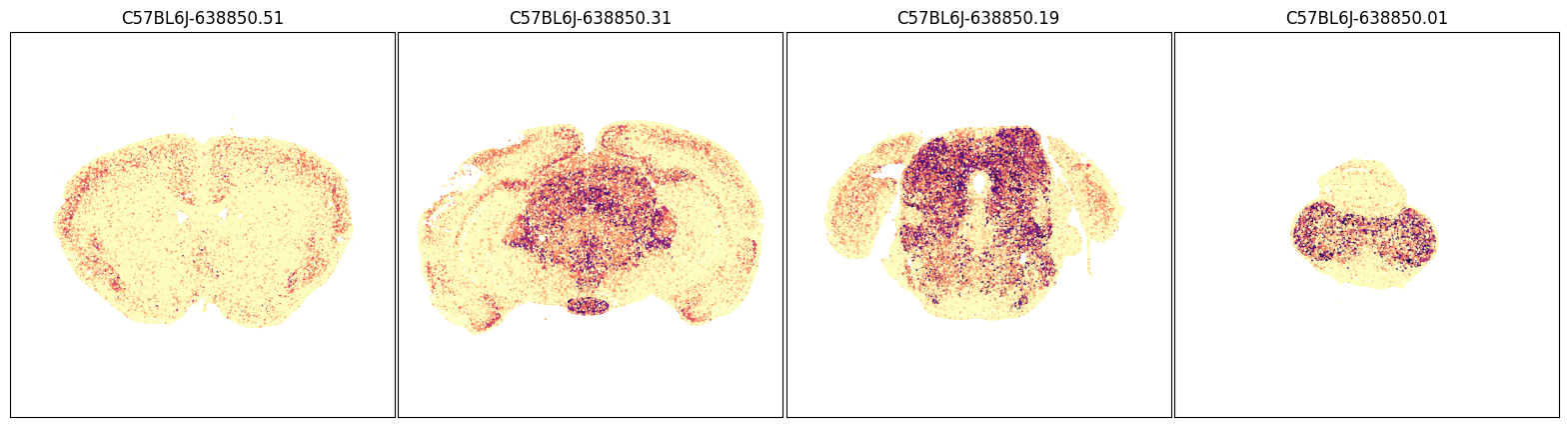
fig, ax = plot_sections(joined, 'Slc17a8', blist, cmap=plt.cm.magma_r)
plt.show()
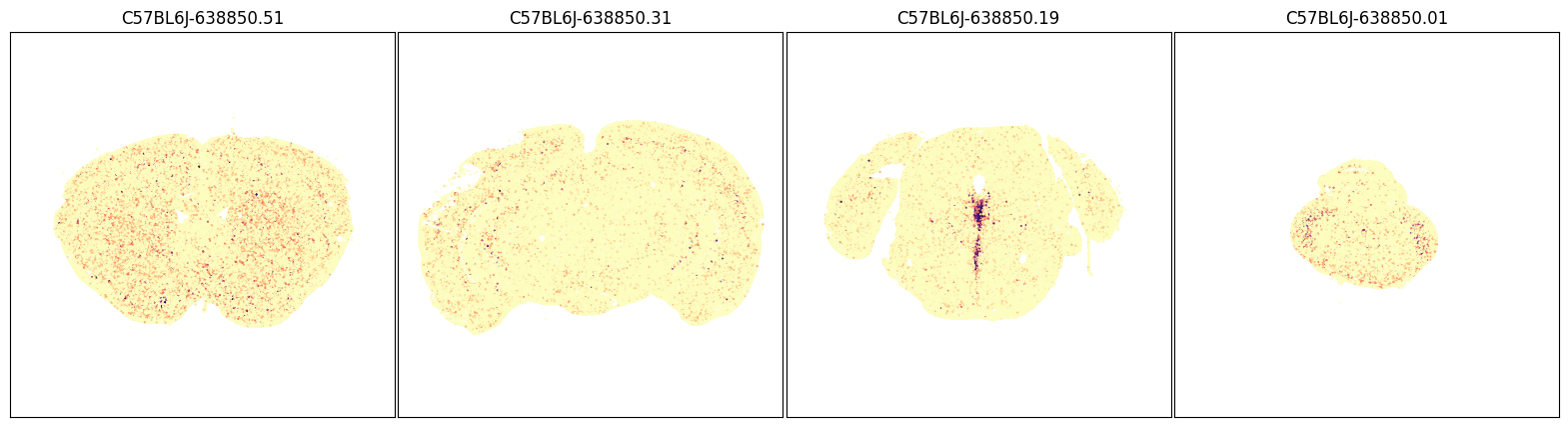
fig, ax = plot_sections(joined, 'Slc32a1', blist, cmap=plt.cm.magma_r)
plt.show()
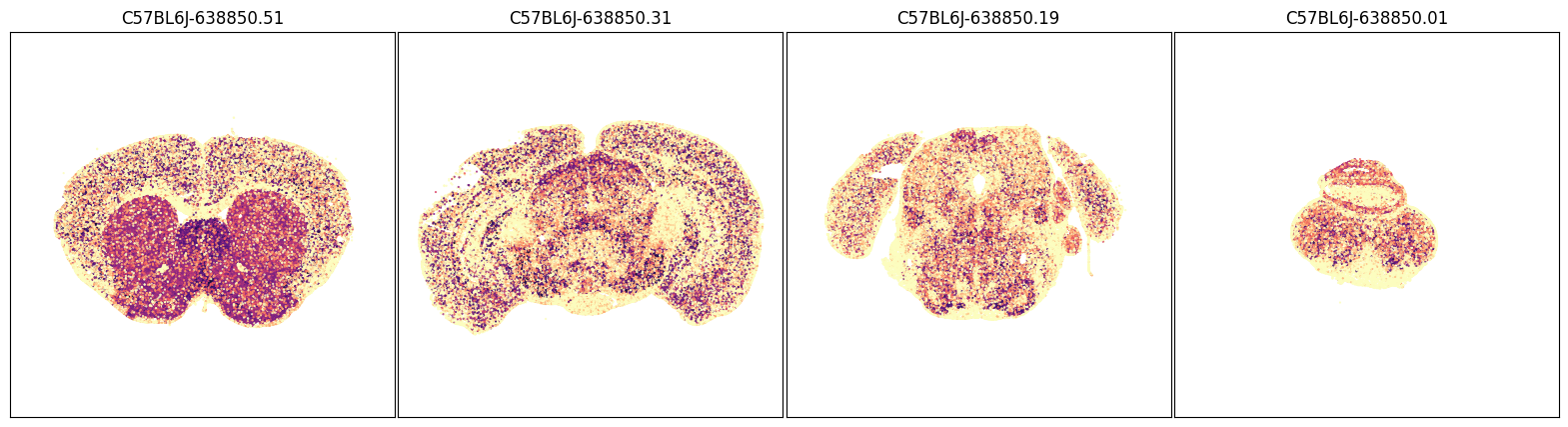
fig, ax = plot_sections(joined, 'Slc6a5', blist, cmap=plt.cm.magma_r)
plt.show()
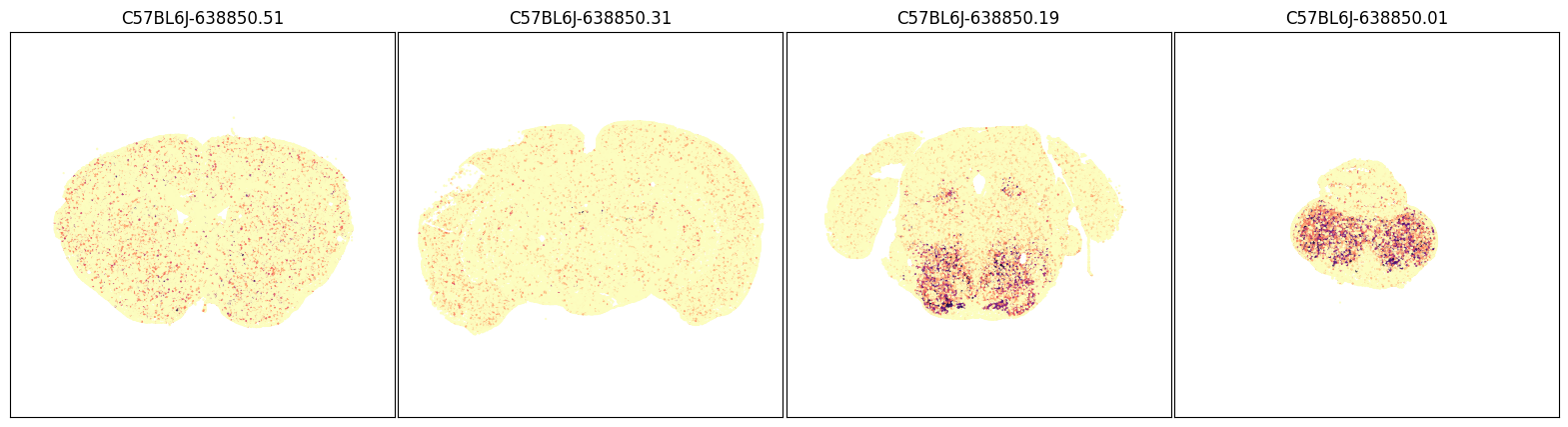
fig, ax = plot_sections(joined, 'Slc6a3', blist, cmap=plt.cm.magma_r)
plt.show()
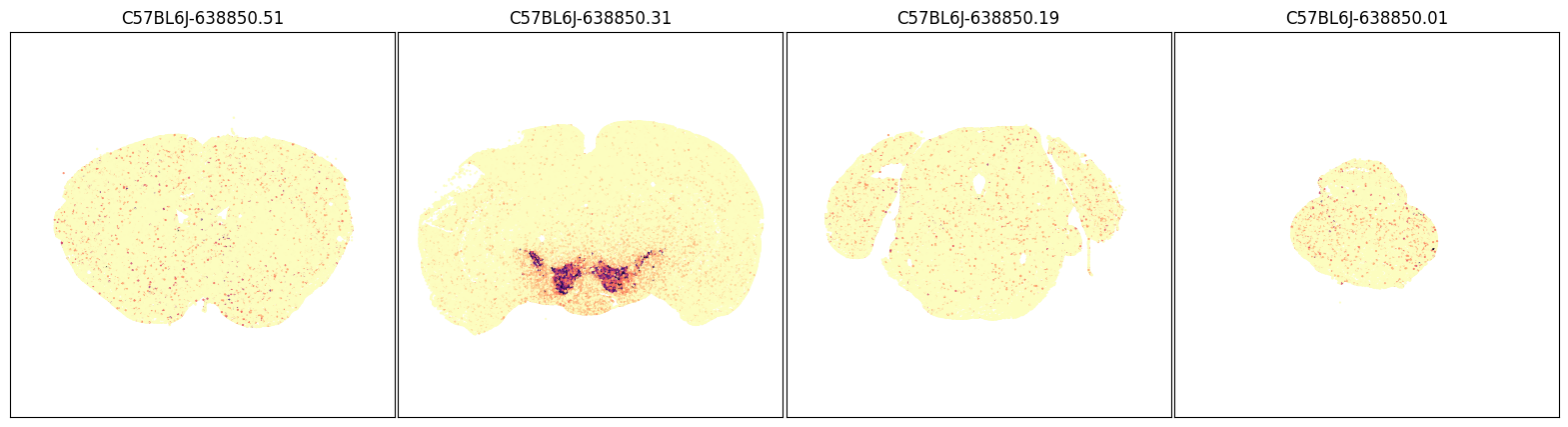
fig, ax = plot_sections(joined, 'Slc6a4', blist, cmap=plt.cm.magma_r)
plt.show()
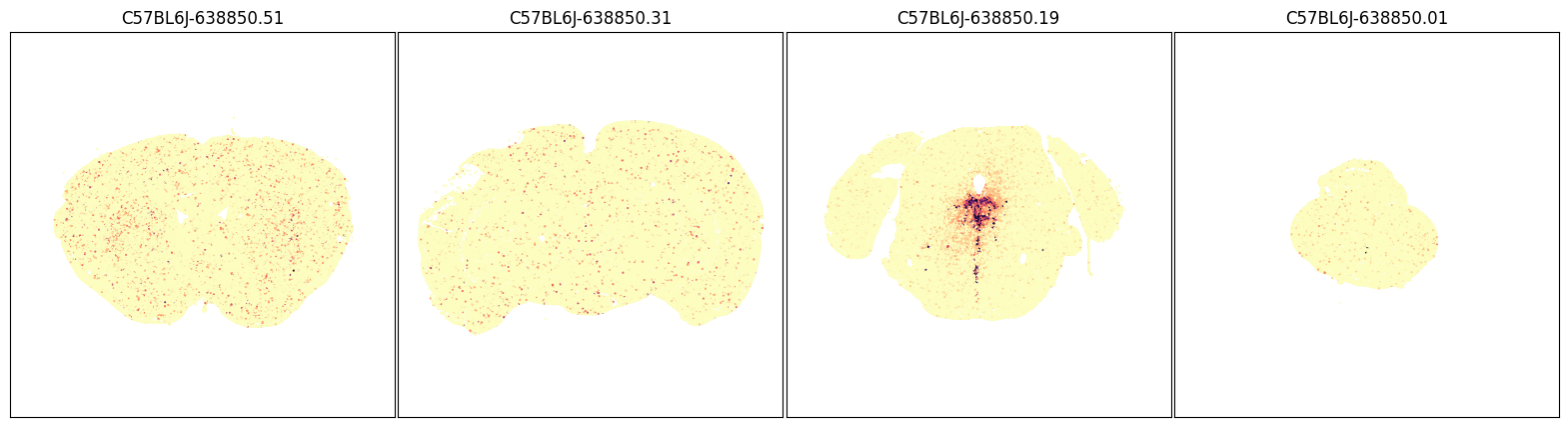
Expression of Tachykinin 2 (Tac2) in the whole brain#
In mice, the tachykinin 2 (Tac2) gene encodes neuropeptide called neurokinin B (NkB). Tac2 is produced by neurons in specific regions of the brain know to be invovled in emotion and social behavior. Based on ISH data from the Allen Mouse Brain Atlas, Tac 2 is sparsely expressed in the mouse isocortex and densely enriched is specific subcortical regions such the medial habenula (MH), the amygdala and hypothalamus.
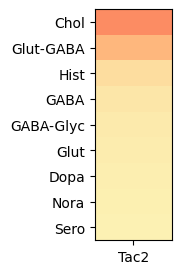
In this example, we create a dataframe comprising expression values of Tac2 for all cells across the whole brain. As with the single brain section example, grouping expression by neurotransmitter show that Tac2 gene is enriched in cholinergic cell types. With the rest of brain included, we can observe that Tac2 is also enriched in Glut-GABA cell types as well.
exgenes = ['Tac2']
filtered = exp[exgenes]
joined = cell.join(filtered)
agg = aggregate_by_metadata(joined, exgenes, 'neurotransmitter', True)
plot_heatmap(agg, 1, 3)
plt.show()
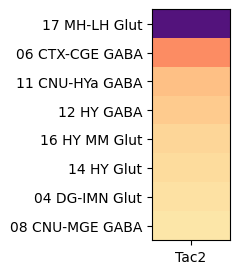
Grouping by class, shows that Tac2 is enriched in class “16 MH-LH Glut” with cells restricted to the medial (MH) and lateral (LH) habenula and a mixture of glutamatergic and cholinergic type and “06 CTX-CGE GABA” GABAergic cells originating from the caudal ganglionic eminence (CGE).
agg = aggregate_by_metadata(joined, exgenes, 'class', True).head(8)
class_list = agg.index[0:2]
plot_heatmap(agg, 1, 3)
plt.show()
At the next level, grouping by subclass reveals enrichment is highly anatomically localized cell types such as the medial habenula (MH), bed nuclei of the stria terminalis (BST), spinal nucleus of the trigeminal (SPVC), main olfactory blub (MOB), central amygdalar nucleus (CEA) and arcuate hypothalamic nucleus (ARH).
agg = aggregate_by_metadata(joined, exgenes, 'subclass', True).head(15)
subclass_list = agg.index[0:10]
plot_heatmap(agg, 1, 3)
plt.show()

The MERFISH data allows us to visualize these spatial pattern in anatomical context. We can aggregate Tac2 expression by brain section so that we can find 4 sections where the enriched expression is located. We then visualize cells in those section by Tac2 expression, neurotransmitter identity, cell type classes and subclasses.
agg = aggregate_by_metadata(joined, exgenes, 'brain_section_label', False)
agg = agg.loc[list(reversed(list(agg.index)))]
plot_heatmap(agg, 1, 11, vmax=0.4)
plt.show()
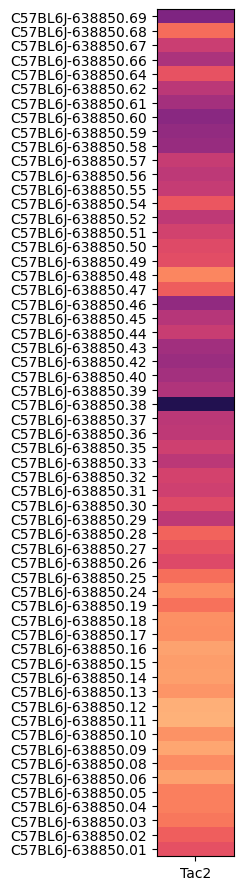
blist = ['C57BL6J-638850.69', 'C57BL6J-638850.46', 'C57BL6J-638850.38', 'C57BL6J-638850.01']
fig, ax = plot_sections(joined, 'Tac2', blist, cmap=plt.cm.magma_r)
plt.show()
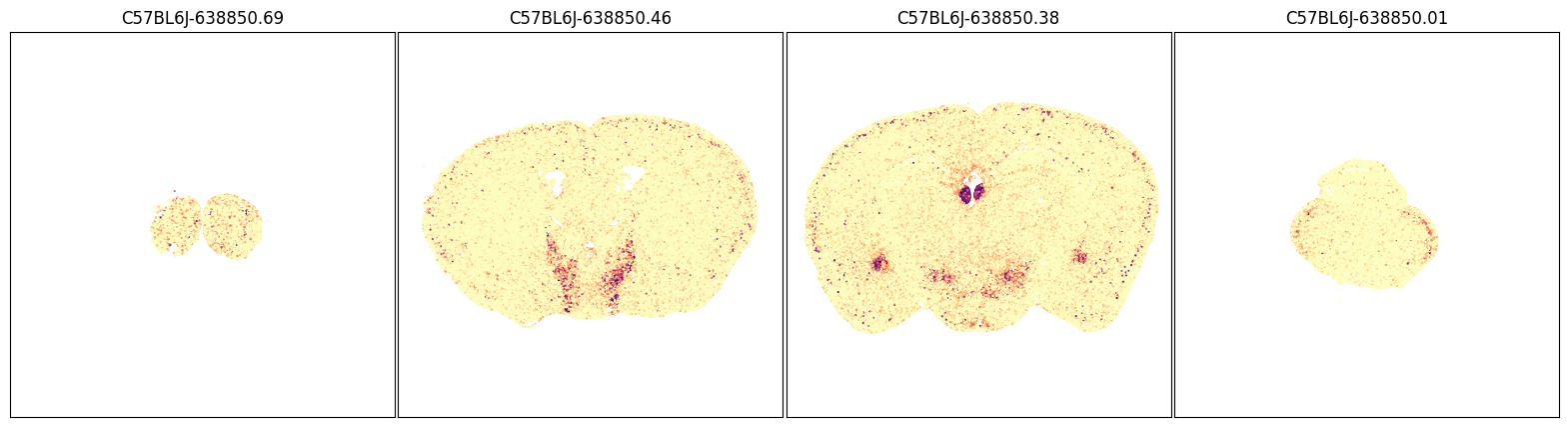
fig, ax = plot_sections(joined, 'neurotransmitter_color', blist, cmap=None)
plt.show()
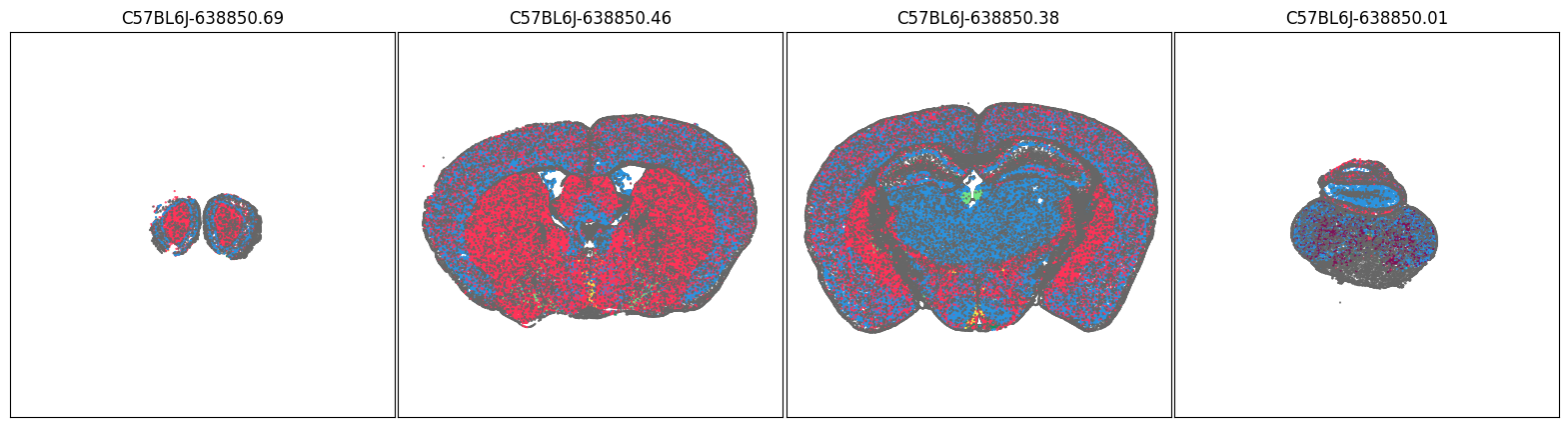
fig, ax = plot_sections(joined, 'class_color', blist, cmap=None)
plt.show()
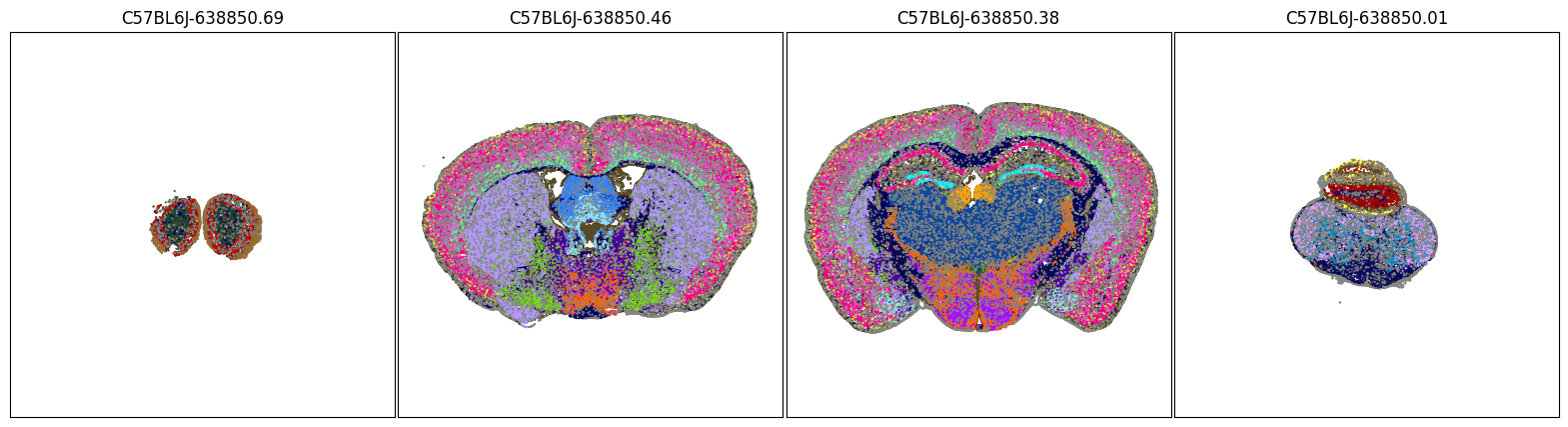
fig, ax = plot_sections(joined, 'subclass_color', blist, cmap=None)
plt.show()
We can use the Tac2 aggregate by subclass table above and pick out the top 10 most enriched subclasses and plot only them on the same set of brain sections and observed that this set of subclasses is able recapitulate the expression pattern of Tac2.
pred = [x in subclass_list for x in joined['subclass']]
filtered = joined[pred]
fig, ax = plot_sections(filtered, 'subclass_color', blist, cmap=None)
plt.show()
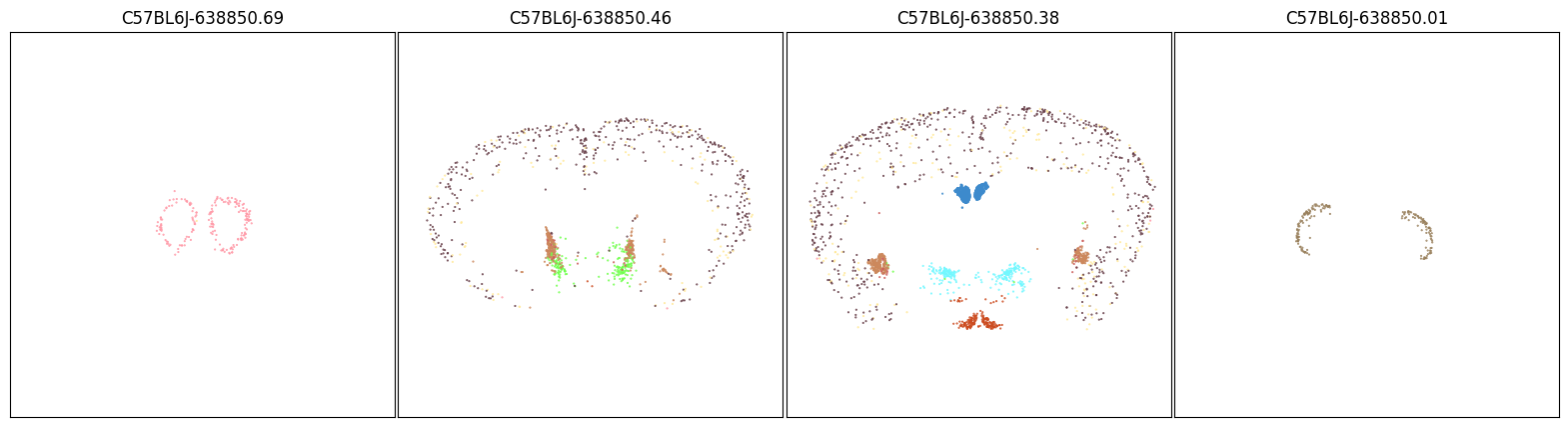
subclass_list
Index(['088 BST Tac2 Gaba', '145 MH Tac2 Glut',
'083 CEA-BST Rai14 Pdyn Crh Gaba', '258 SPVC Nmu Glut',
'043 OB-mi Frmd7 Gaba', '047 Sncg Gaba', '082 CEA-BST Ebf1 Pdyn Gaba',
'046 Vip Gaba', '103 PVHd-DMH Lhx6 Gaba', '126 ARH-PVp Tbx3 Glut'],
dtype='object', name='subclass')