Contributing to the Databook#
The OpenScope Databook is a community project. It aims to serve as a collection of contributed analyses from many different experts and to include a comprehensive set of useful and reproducible analyses. Contributors are added to the authors list and have an opportunity to share their figures, results, and datasets through their notebooks in the Databook. Together the project can grow and continue to shape the growing reproducible neuroscience ecosystem.
Fork the OpenScope Databook#
The Databook can be forked via the GitHub Web UI from the Databook’s GitHub repo. Press the fork button or click this link.
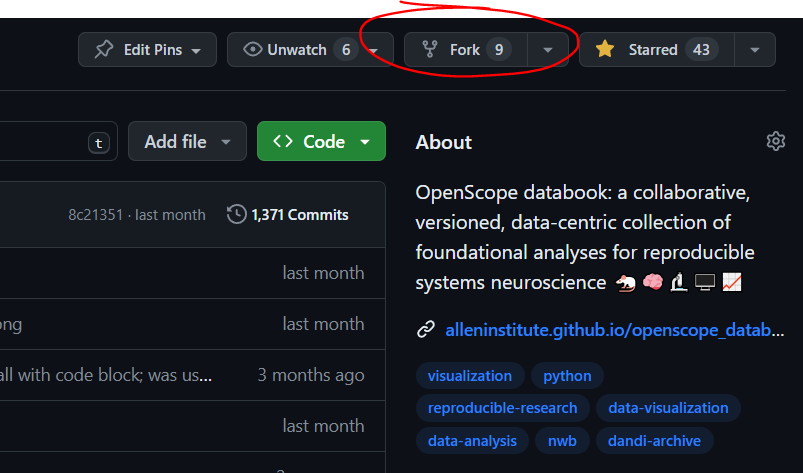{kind=link}
Initialize Locally#
A local repo can be made by pressing the code button on the front page of the forked repo, and copying the HTTPS url. Then locally, run the command git clone <copied_url_here>. For more information on cloning GitHub repos, check out GitHub’s Cloning a Repository Page.
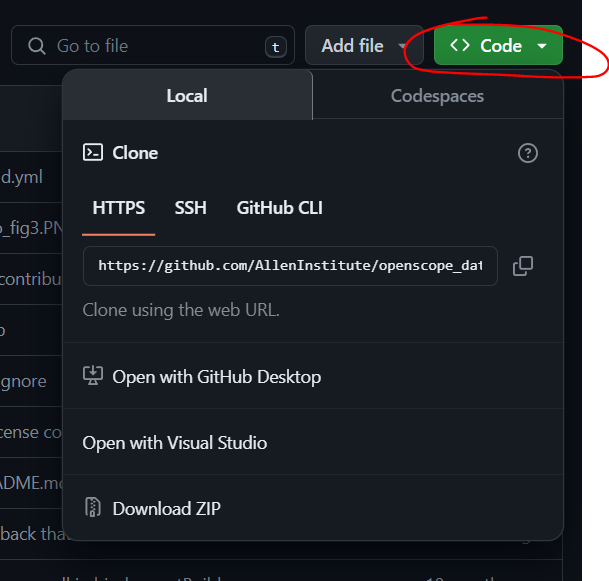{kind=link}
Then the environment must be set up. The preferred local setup is Python 3.10 with uv, which mirrors CI and lockfile resolution. After cloning, run python -m pip install uv followed by uv sync --frozen --extra dev --python 3.10. If you prefer not to use uv, create a Python 3.10 environment and install with python -m pip install -r requirements-ci.txt and python -m pip install -e ..
Finally, notebooks can be run with Jupyter notebook by running uv run jupyter notebook ./docs (or jupyter notebook ./docs in an already-activated pip environment).
Make Contributions#
A contribution can take the form of changes to an existing notebook. More likely, it will be in adding a new analysis notebook to the databook. First, determine which chapter it will go into within the ./docs directory, and create a new .ipynb file there. Then the notebook can be produced with the analysis and reproducible figures. For a contribution to be accepted it must adhere to the contribution Styleguide below. In addition to having clean code and clear figures, it is important that the notebook has thorough markdown explaining the figures and the analysis performed.
Important Note: For a notebook to be compliant with the Databook, it must have an environment setup cell at the top. This is described in the Styleguide below.
Any additional packages required for the notebook to run should be added to pyproject.toml, then lock/export artifacts should be updated with uv lock and uv export --frozen --no-dev --no-emit-project --no-hashes -o requirements-ci.txt. When the notebook is complete it must be added to docs/_toc.yml to the appropriate chapter.
Run and Test Locally#
Prior to pushing, the notebook should be tested locally. It should be ensured that it runs from beginning to end without interruption and produces clean-looking figures. To confirm everything is configured properly, the Jupyter book should be built and examined with the command jupyter-book build ./docs.
Commit, Push and Make a Pull Request#
Local progress can be saved with git commit and then pushed to the remote fork with git push. See this Git tutorial for more information on how to do this.
A PR can then be made to the original OpenScope Databook repo. On the forked repo front page, first make sure to press the sync fork button, and then contribute can be pressed to make a PR. It is advised to make the PR into the Databook’s dev branch rather than the main branch.
Interact on ReviewNB#
Once the pull request is made, it will be reviewed for merging into the Databook. This process can be monitored on the PR page, where there will be a purple button linking to ReviewNB. ReviewNB allows for the additions and changes made to notebooks to be easily viewed and commented on. Please check this for any feedback provided by the Databook team and make revisions accordingly. Once the PR is merged, you will be added to the authors list of the Databook.
Reviewing the Databook#
Reviews of the Databook are also made on GitHub via Git commits. We recommend you make a local fork of this repository and create a PR with your edits that either correct or extend a given notebook as discussed in the various sections above. If you feel like a notebook should be discussed, please first make a PR request and enter your reviewing comment on the PR form on GitHub with ReviewNB. You are free to choose any page of the databook for reviews, depending on your expertise and time. According to the authorship section below, reviewers gain authorship if they propose modifications that are eventually merged into the main branch.
Styleguide#
Each notebook should begin with a markdown cell containing one pound sign
#and a title. Provide an brief description of the dataset and an overview of the notebook and purpose of the analysis. Relevant background information on the tools used or the analysis conducted should be mentioned.The first section should be
# Environment Setup. The first code cell here should include all the import statements within the notebook. With rare exceptions, in order for the notebook to be compliant with the databook’s usage on all platforms, the cell containing the requirements installation must be included. The cell should resemble the following:
try:
from databook_utils.dandi_utils import dandi_download_open
except:
!git clone https://github.com/AllenInstitute/openscope_databook.git
%cd openscope_databook
%pip install -e .
Supplemental information, cited works, and other notebooks should be linked and cited where possible. Links to other notebooks in the databook with related information are strongly advised. For citations, the reference should be added to
references.biband in text citations should use Jupyter Book syntax like the following:
{cite}`Lecoq2024`
The heading of sections should begin with three pound signs
##and to the extent that is necessary, describe the purpose of the following section and an overview of what the following code does.The purpose of functions that are defined should be briefly described in the section heading markdown cells.
In markdown, conceptual keywords should be italicized, packages and tool names should be bolded, and variables, methods and filenames should be
ticked.The major parameters of the notebook that are intended to be easily modified by users should exist in their own code cell at the top of their relevant section with appropriate description, i.e. something like
bin_size = 0.01 # bin size in seconds
window_start_time = -1 # time relative to the stimulus to start the histogram
window_end_time = 3 # time relative to the stimulus to end the histogram
Comments should be supplied to specific lines or snippets to describe how they work, or for what specific purpose they serve. General purposes and descriptions of cells or groups of cells are better described in markdown of the relevant section.
Variables and Functions should be given descriptive names
Cells shouldn’t be too long and should serve one purpose. Large blocks of code should be split into functions and into self-contained cells.
Intermediate processing steps should be displayed or plotted to the extent that they are helpful. In general, it is a good idea to show what the data look like during these critical transformations.
Code to plot data should be in their own code cells, separate from the code to manipulate data
Figures should contain labeled axes and titles.