Advanced Methods for Driving your Network with Synaptic Spike-trains#
BMTK is designed to build and simulate large-scale, realistic models of the nervous system. Most of these realistic simulations require the ability to recreate the kinds of synaptic input you would expect to see in vivo. To achieve this, modelers need to be able to generate the relevant spike trains that drive the synaptic stimuli of our simulations.
We have other tutorials demonstrating how to generate realistic stimuli using FilterNet. We have also shown how to use the BMTK SpikeTrain and PoissonSpikeTrain classes to generate input spike trains. In these cases, users must generate SONATA spike-train files before running their simulations. However, BMTK has additional methods for users to generate and import spike-train stimuli into their simulations. It includes using other formats besides SONATA, importing experimental data, and more fine-grained control of how and where cells within a network receive synaptic stimuli.
We will cover some of such methods in this tutorial.
Note - scripts and files for running this tutorial can be found in the directory 03_opt_advanced_spiking_inputs/
1. Example: Using spikes from CSV#
In Tutorial 2, we demonstrated how to generate network spikes using the BMTK’s built-in PoissonSpikeGenerator class, which will produce a series of spike trains using the distribution parameters/functions we give it and save it to a SONATA spikes file using to to_sonata method. But BMTK also allows input spikes to be saved and loaded using a simpler space-separated CSV file, which, in many cases, can be
easier to analyze and use with other programs.
For example, in the network_simple_spikes/ folder (built using build_network.simple_spikes.py), we have a set of 10 virtual nodes that synaptically drive our simulation. If we want each one to fire at a constant 10Hz firing rate over a 5-second interval, we can use PoissonSpikeGenerator’s to_csv() class to save the spikes as a CSV file.
[1]:
from bmtk.utils.reports.spike_trains import PoissonSpikeGenerator
psg = PoissonSpikeGenerator()
psg.add(
node_ids='network_csv_spikes/inputs_nodes.h5',
firing_rate=10.0,
times=(0.0, 5.0),
population='inputs'
)
psg.to_csv('inputs/simple_spikes.csv')
Now, we can use any text editor or CSV reader (like pandas) to read in our spikes for verification and analysis.
[2]:
import pandas as pd
spikes_inputs = pd.read_csv('inputs/simple_spikes.csv', sep=' ')
# Let's quickly check that our csv file makes sense
n_nodes = spikes_inputs['node_ids'].unique().shape[0]
n_spikes = spikes_inputs.shape[0]
print(f'Number of cells in spikes-file: {n_nodes} (expected: 5)')
print(f'Avg. number of spikes per cell: {n_spikes/n_nodes} (expected: 5sec x 10Hz ~ 50)')
print(f'Min spike-time: {spikes_inputs["timestamps"].min()} ms')
print(f'Max spike-time: {spikes_inputs["timestamps"].max()} ms')
spikes_inputs.head()
Number of cells in spikes-file: 10 (expected: 5)
Avg. number of spikes per cell: 50.1 (expected: 5sec x 10Hz ~ 50)
Min spike-time: 17.593944539645307 ms
Max spike-time: 4998.560456807771 ms
[2]:
| timestamps | population | node_ids | |
|---|---|---|---|
| 0 | 40.425085 | inputs | 0 |
| 1 | 326.168408 | inputs | 0 |
| 2 | 434.783000 | inputs | 0 |
| 3 | 821.277923 | inputs | 0 |
| 4 | 847.735538 | inputs | 0 |
Then, when running the simulation, we can do so as we previously did with SONATA spike files, but the difference is that the module type for the given input must be changed from sonata to csv:
```json “inputs”: { “csv_spikes”: { “input_type”: “spikes”, “module”: “csv”, “input_file”: “./inputs/simple_spikes.csv”, “node_set”: “inputs” } },
Creating your own csv file#
You can create your own spike-train CSV file if you don’t want to use the PoissonSpikeGenerator class. As we can see from above, it needs to be a space-separated text file with columns timestamps, population, and node_ids (order doesn’t matter). Each row indicates a separate spike, with the population + node_ids columns indicating the node/cell that fired and timestamps (in milliseconds) indicating when it fired.
For example, we can use the Python CSV writer class to create an example input file where each cell has an increasing firing rate.
[3]:
import csv
import numpy as np
with open('inputs/custom_spikes.csv', 'w') as csvfile:
csvwriter = csv.writer(csvfile, delimiter=' ', quotechar='#')
# write the header
csvwriter.writerow(['timestamps', 'population', 'node_ids'])
# For node 0 we have it fire randomly at 1 Hz for 5 seconds, for node 1 at 2Hz, etc.
for node_id in range(10):
for timestamp in np.sort(np.random.uniform(0.0, 5000.0, size=(node_id+1)*5)):
csvwriter.writerow([timestamp, 'inputs', node_id])
[4]:
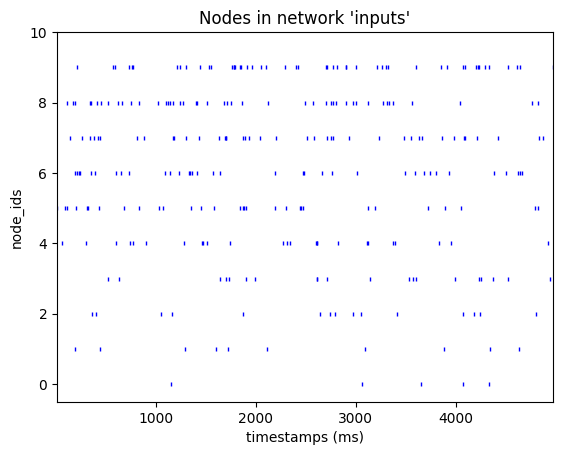
from bmtk.analyzer.spike_trains import plot_raster
_ = plot_raster(spikes_file='inputs/custom_spikes.csv', with_histogram=False)
Remember: Biophysical models contain customized ion channels that require compiling using the nrnivmod command before running Bionet (see Tutorial 1 for more details). Ion channels are stored in the components/mechanisms/mod/ folder. In a shell or using Jupyter notebook, you’ll need to run the following:
[5]:
! cd components/mechanisms && nrnivmodl modfiles
/opt/conda/bin/nrnivmodl:10: DeprecationWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html
from pkg_resources import working_set
/home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms
Mod files: "modfiles/modfiles/CaDynamics.mod" "modfiles/modfiles/Ca_HVA.mod" "modfiles/modfiles/Ca_LVA.mod" "modfiles/modfiles/Ih.mod" "modfiles/modfiles/Im.mod" "modfiles/modfiles/Im_v2.mod" "modfiles/modfiles/K_P.mod" "modfiles/modfiles/K_T.mod" "modfiles/modfiles/Kd.mod" "modfiles/modfiles/Kv2like.mod" "modfiles/modfiles/Kv3_1.mod" "modfiles/modfiles/NaTa.mod" "modfiles/modfiles/NaTs.mod" "modfiles/modfiles/NaV.mod" "modfiles/modfiles/Nap.mod" "modfiles/modfiles/SK.mod" "modfiles/modfiles/exp1isyn.mod" "modfiles/modfiles/exp1syn.mod" "modfiles/modfiles/stp1syn.mod" "modfiles/modfiles/stp2syn.mod" "modfiles/modfiles/stp3syn.mod" "modfiles/modfiles/stp4syn.mod" "modfiles/modfiles/stp5isyn.mod" "modfiles/modfiles/stp5syn.mod" "modfiles/modfiles/vecevent.mod"
Creating 'x86_64' directory for .o files.
-> Compiling mod_func.cpp
-> NMODL ../modfiles/CaDynamics.mod
-> NMODL ../modfiles/Ca_HVA.mod
-> NMODL ../modfiles/Ca_LVA.mod
Translating Ca_HVA.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/Ca_HVA.c
Translating Ca_LVA.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/Ca_LVA.c
Translating CaDynamics.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/CaDynamics.c
Thread Safe
Thread Safe
Thread Safe
-> NMODL ../modfiles/Ih.mod
-> NMODL ../modfiles/Im_v2.mod
-> NMODL ../modfiles/Im.mod
Translating Im_v2.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/Im_v2.c
Translating Ih.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/Ih.c
Translating Im.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/Im.c
Thread Safe
-> NMODL ../modfiles/K_P.mod
Thread Safe
Thread Safe
-> NMODL ../modfiles/K_T.mod
-> NMODL ../modfiles/Kd.mod
Translating K_P.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/K_P.c
Translating K_T.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/K_T.c
Translating Kd.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/Kd.c
Thread Safe
Thread Safe
Thread Safe
-> NMODL ../modfiles/Kv2like.mod
-> NMODL ../modfiles/Kv3_1.mod
-> NMODL ../modfiles/NaTa.mod
Translating Kv2like.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/Kv2like.c
Translating Kv3_1.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/Kv3_1.c
Translating NaTa.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/NaTa.c
Thread Safe
Thread Safe
Thread Safe
-> NMODL ../modfiles/NaTs.mod
-> NMODL ../modfiles/NaV.mod
-> NMODL ../modfiles/Nap.mod
Translating NaTs.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/NaTs.c
Translating NaV.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/NaV.c
Translating Nap.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/Nap.c
NEURON's CVode method ignores conservation
Notice: LINEAR is not thread safe.
Thread Safe
Thread Safe
-> NMODL ../modfiles/SK.mod
-> NMODL ../modfiles/exp1syn.mod
-> NMODL ../modfiles/exp1isyn.mod
Translating SK.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/SK.c
Translating exp1syn.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/exp1syn.c
Translating exp1isyn.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/exp1isyn.c
Thread Safe
Thread Safe
Thread Safe
-> NMODL ../modfiles/stp1syn.mod
-> NMODL ../modfiles/stp2syn.mod
-> NMODL ../modfiles/stp3syn.mod
Translating stp1syn.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/stp1syn.c
Translating stp2syn.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/stp2syn.c
Translating stp3syn.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/stp3syn.c
Thread Safe
Thread Safe
Thread Safe
-> NMODL ../modfiles/stp4syn.mod
-> NMODL ../modfiles/stp5isyn.mod
-> NMODL ../modfiles/stp5syn.mod
Translating stp4syn.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/stp4syn.c
Translating stp5isyn.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/stp5isyn.c
Translating stp5syn.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/stp5syn.c
Thread Safe
Thread Safe
Thread Safe
-> NMODL ../modfiles/vecevent.mod
-> Compiling CaDynamics.c
-> Compiling Ca_HVA.c
Translating vecevent.mod into /home/shared/bmtk-workshop/docs/tutorial/03_opt_advanced_spiking_inputs/components/mechanisms/x86_64/vecevent.c
Notice: VERBATIM blocks are not thread safe
-> Compiling Ca_LVA.c
-> Compiling Ih.c
-> Compiling Im.c
-> Compiling Im_v2.c
-> Compiling K_P.c
-> Compiling K_T.c
-> Compiling Kd.c
-> Compiling Kv2like.c
-> Compiling Kv3_1.c
-> Compiling NaTa.c
-> Compiling NaTs.c
-> Compiling NaV.c
-> Compiling Nap.c
-> Compiling SK.c
-> Compiling exp1isyn.c
-> Compiling exp1syn.c
-> Compiling stp1syn.c
-> Compiling stp2syn.c
-> Compiling stp3syn.c
-> Compiling stp4syn.c
-> Compiling stp5isyn.c
-> Compiling stp5syn.c
-> Compiling vecevent.c
=> LINKING shared library ./libnrnmech.so
=> LINKING executable ./special LDFLAGS are: -pthread
Successfully created x86_64/special
We can now run the simulation with our custom CSV input file.
[6]:
from bmtk.simulator import bionet
from bmtk.analyzer.spike_trains import plot_raster, to_dataframe
bionet.reset()
conf = bionet.Config.from_json('config.csv_spikes.json')
conf.build_env()
net = bionet.BioNetwork.from_config(conf)
sim = bionet.BioSimulator.from_config(conf, network=net)
sim.run()
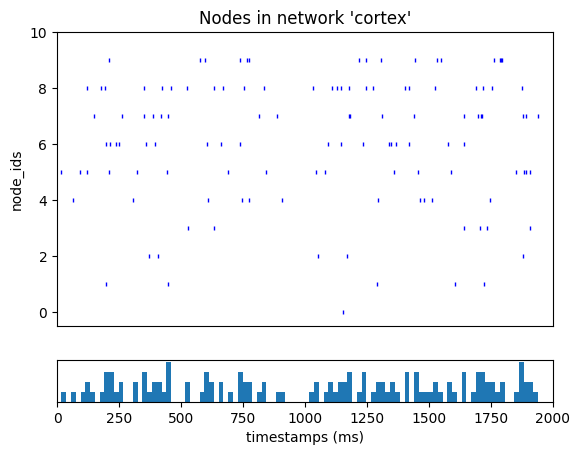
_ = plot_raster(config_file='config.csv_spikes.json')
2024-10-24 00:02:57,330 [INFO] Created log file
2024-10-24 00:02:57,418 [INFO] Building cells.
Warning: no DISPLAY environment variable.
--No graphics will be displayed.
2024-10-24 00:02:58,097 [INFO] Building recurrent connections
2024-10-24 00:02:58,102 [INFO] Building virtual cell stimulations for LGN_spikes_sonata
2024-10-24 00:02:58,137 [INFO] Running simulation for 2000.000 ms with the time step 0.100 ms
2024-10-24 00:02:58,138 [INFO] Starting timestep: 0 at t_sim: 0.000 ms
2024-10-24 00:02:58,138 [INFO] Block save every 5000 steps
2024-10-24 00:02:58,492 [INFO] step:5000 t_sim:500.00 ms
2024-10-24 00:02:58,839 [INFO] step:10000 t_sim:1000.00 ms
2024-10-24 00:02:59,176 [INFO] step:15000 t_sim:1500.00 ms
2024-10-24 00:02:59,514 [INFO] step:20000 t_sim:2000.00 ms
2024-10-24 00:02:59,549 [INFO] Simulation completed in 1.412 seconds
2. Example: Dynamically generating custom spike-trains#
Pregenerating spike trains for your simulations inside an hdf5 or CSV file is computationally efficient and makes your results more accessible to reproduce and share. However, at times, it may be beneficial for users to generate spike trains dynamically during each simulation. If you are doing quick simulations and spot-checks, it can be cumbersome having to regenerate a file beforehand. Or if a user is running thousands of simulations or doing some kind of gradient search, the cost of potentially creating thousands of spike files beforehand may not be reasonable.
BMTK also allows modelers to create their own special function, which will generate new spike trains at the start of each simulation. To do so, you only need to make changes to the configuration for a “spikes” input so that the module is set to value function, and instead of spikes_input, you specify a spikes_function parameter that will be the name of your custom function.
"inputs": {
"LGN_spikes_sonata": {
"input_type": "spikes",
"module": "function",
"spikes_function": "my_spikes_generator",
"node_set": "LGN"
}
}
For BMTK to know where to find the my_spikes_generator, you must then use the @spikes_generator at the top of a given function in your run_bmtk.py script (or any python file imported into the run script). In the below example, we use the following to return spike trains for every cell in the LGN node_set to fire at a constant rate (although different rates for different models).
[7]:
from bmtk.simulator.bionet.io_tools import io
from bmtk.simulator.bionet import spikes_generator
import numpy as np
@spikes_generator
def my_spikes_generator(node, sim):
io.log_info(f'Generating custom spike trains for node {node.node_id} from {node.population_name}')
if node['pop_name'] == 'tON':
return np.arange(100.0, sim.tstop, step=sim.dt*10)
elif node['pop_name'] == 'tOFF':
return np.arange(100.0, sim.tstop, step=sim.dt*20)
else:
return []
All
spikes_generatorfunctions must have parametersnodeandsim.nodeallows you to access information about each node/cell like a dictionary.simis a class containing information about a current simulation, including information like start time (sim.tstart), stop_time (sim.tstop), step size (sim.dt), among other properties.
The
spikes_generatorshould return either a list or array of timestamps, in milliseconds, for each node.We include a logging statement for good measure. This is not required, but it is good for debugging and checking that our custom function is being called.
When the simulation is running, the my_spikes_generator function will be called once for each node in the specified node_set.
[8]:
from bmtk.simulator import bionet
bionet.reset()
conf = bionet.Config.from_json('config.spikes_generator.json')
conf.build_env()
net = bionet.BioNetwork.from_config(conf)
sim = bionet.BioSimulator.from_config(conf, network=net)
sim.run()
2024-10-24 00:02:59,673 [INFO] Created log file
Mechanisms already loaded from path: ./components/mechanisms. Aborting.
2024-10-24 00:02:59,707 [INFO] Building cells.
2024-10-24 00:03:06,517 [INFO] Building recurrent connections
2024-10-24 00:03:06,532 [INFO] Building virtual cell stimulations for LGN_spikes_sonata
2024-10-24 00:03:06,545 [INFO] Generating custom spike trains for 0 from LGN
2024-10-24 00:03:06,549 [INFO] Generating custom spike trains for 28 from LGN
2024-10-24 00:03:06,550 [INFO] Generating custom spike trains for 27 from LGN
2024-10-24 00:03:06,551 [INFO] Generating custom spike trains for 14 from LGN
2024-10-24 00:03:06,552 [INFO] Generating custom spike trains for 2 from LGN
2024-10-24 00:03:06,553 [INFO] Generating custom spike trains for 38 from LGN
2024-10-24 00:03:06,554 [INFO] Generating custom spike trains for 26 from LGN
2024-10-24 00:03:06,555 [INFO] Generating custom spike trains for 15 from LGN
2024-10-24 00:03:06,556 [INFO] Generating custom spike trains for 25 from LGN
2024-10-24 00:03:06,557 [INFO] Generating custom spike trains for 16 from LGN
2024-10-24 00:03:06,558 [INFO] Generating custom spike trains for 24 from LGN
2024-10-24 00:03:06,568 [INFO] Generating custom spike trains for 17 from LGN
2024-10-24 00:03:06,572 [INFO] Generating custom spike trains for 1 from LGN
2024-10-24 00:03:06,573 [INFO] Generating custom spike trains for 39 from LGN
2024-10-24 00:03:06,577 [INFO] Generating custom spike trains for 23 from LGN
2024-10-24 00:03:06,578 [INFO] Generating custom spike trains for 18 from LGN
2024-10-24 00:03:06,580 [INFO] Generating custom spike trains for 12 from LGN
2024-10-24 00:03:06,581 [INFO] Generating custom spike trains for 22 from LGN
2024-10-24 00:03:06,582 [INFO] Generating custom spike trains for 29 from LGN
2024-10-24 00:03:06,583 [INFO] Generating custom spike trains for 11 from LGN
2024-10-24 00:03:06,584 [INFO] Generating custom spike trains for 5 from LGN
2024-10-24 00:03:06,585 [INFO] Generating custom spike trains for 35 from LGN
2024-10-24 00:03:06,586 [INFO] Generating custom spike trains for 6 from LGN
2024-10-24 00:03:06,587 [INFO] Generating custom spike trains for 36 from LGN
2024-10-24 00:03:06,588 [INFO] Generating custom spike trains for 34 from LGN
2024-10-24 00:03:06,589 [INFO] Generating custom spike trains for 7 from LGN
2024-10-24 00:03:06,590 [INFO] Generating custom spike trains for 4 from LGN
2024-10-24 00:03:06,591 [INFO] Generating custom spike trains for 33 from LGN
2024-10-24 00:03:06,592 [INFO] Generating custom spike trains for 8 from LGN
2024-10-24 00:03:06,593 [INFO] Generating custom spike trains for 32 from LGN
2024-10-24 00:03:06,594 [INFO] Generating custom spike trains for 9 from LGN
2024-10-24 00:03:06,595 [INFO] Generating custom spike trains for 37 from LGN
2024-10-24 00:03:06,596 [INFO] Generating custom spike trains for 31 from LGN
2024-10-24 00:03:06,597 [INFO] Generating custom spike trains for 10 from LGN
2024-10-24 00:03:06,598 [INFO] Generating custom spike trains for 30 from LGN
2024-10-24 00:03:06,599 [INFO] Generating custom spike trains for 3 from LGN
2024-10-24 00:03:06,599 [INFO] Generating custom spike trains for 19 from LGN
2024-10-24 00:03:06,601 [INFO] Generating custom spike trains for 13 from LGN
2024-10-24 00:03:06,602 [INFO] Generating custom spike trains for 21 from LGN
2024-10-24 00:03:06,602 [INFO] Generating custom spike trains for 20 from LGN
2024-10-24 00:03:07,466 [INFO] Running simulation for 2000.000 ms with the time step 0.100 ms
2024-10-24 00:03:07,466 [INFO] Starting timestep: 0 at t_sim: 0.000 ms
2024-10-24 00:03:07,467 [INFO] Block save every 5000 steps
2024-10-24 00:03:17,745 [INFO] step:5000 t_sim:500.00 ms
2024-10-24 00:03:28,232 [INFO] step:10000 t_sim:1000.00 ms
2024-10-24 00:03:38,876 [INFO] step:15000 t_sim:1500.00 ms
2024-10-24 00:03:49,440 [INFO] step:20000 t_sim:2000.00 ms
2024-10-24 00:03:49,465 [INFO] Simulation completed in 42.0 seconds
3. Example: Incorporating real data from NWB files#
You can use tools like FilterNet or PoissonSpikeGenerator to create theoretical-to-realistic synaptic stimuli onto a network from various modes. But better yet, when actual experimental data is available, it is often possible to use just that. Especially as more and more experimental electrophysiological data sets are being made publicly available through resources like DANDI or The Allen Brain Observatory, we will want not only to use such data as a base-line for validating our models and comparing them to experiments, but also to use the data within specific simulations. For example, when modeling a network of one population and/or region, we will want to use recordings of surrounding cells to help excite and inhibit our cells more realistically.
Traditionally a major issue with encorporating experimental electrophysiology data into simulations is trying to parse the wide variety of different ways the data was stored. Luckily, the Neurodata Without Borders (NWB) has developed a format for storing experimental data, which has seen a substantial amount of adoption in the field. BMTK can take these files and automatically insert them into simulations.
In this example, we will take the previous model of the Mouse Primary Visual Cortex and add inputs that we know come from higher cortical regions (in this case, just the VisL and subcortical regions) along with the input from the LGN. For these added regions, we will use actual Neuropixels recordings of activity from these regions during presentation of drifting gratings.
Step 1: Download the data#
The first step is to find experimental NWB that includes spiking events. For our example, we will use data from Allen Institute Visual Coding dataset downloaded using the AllenSDK. We will get three experimental sessions that we know contain recordings of the VisL and hippocampus.
[1]:
from allensdk.brain_observatory.ecephys.ecephys_project_cache import EcephysProjectCache
cache = EcephysProjectCache.from_warehouse(
manifest='./ecephys_cache_dir/neuropixels.manifest.json'
)
cache.get_session_data(715093703)
cache.get_session_data(798911424)
cache.get_session_data(754829445)
WARNING:root:downloading a 2723.916MiB file from http://api.brain-map.org//api/v2/well_known_file_download/1026124469
/opt/anaconda3/envs/biorealistic-v1/lib/python3.11/site-packages/hdmf/utils.py:668: UserWarning: Ignoring cached namespace 'hdmf-common' version 1.1.3 because version 1.8.0 is already loaded.
return func(args[0], **pargs)
/opt/anaconda3/envs/biorealistic-v1/lib/python3.11/site-packages/hdmf/utils.py:668: UserWarning: Ignoring cached namespace 'core' version 2.2.2 because version 2.7.0 is already loaded.
return func(args[0], **pargs)
WARNING:root:downloading a 2731.587MiB file from http://api.brain-map.org//api/v2/well_known_file_download/1026124743
/opt/anaconda3/envs/biorealistic-v1/lib/python3.11/site-packages/hdmf/utils.py:668: UserWarning: Ignoring cached namespace 'hdmf-common' version 1.1.3 because version 1.8.0 is already loaded.
return func(args[0], **pargs)
/opt/anaconda3/envs/biorealistic-v1/lib/python3.11/site-packages/hdmf/utils.py:668: UserWarning: Ignoring cached namespace 'core' version 2.2.2 because version 2.7.0 is already loaded.
return func(args[0], **pargs)
WARNING:root:downloading a 2571.776MiB file from http://api.brain-map.org//api/v2/well_known_file_download/1026124326
/opt/anaconda3/envs/biorealistic-v1/lib/python3.11/site-packages/hdmf/utils.py:668: UserWarning: Ignoring cached namespace 'hdmf-common' version 1.1.3 because version 1.8.0 is already loaded.
return func(args[0], **pargs)
/opt/anaconda3/envs/biorealistic-v1/lib/python3.11/site-packages/hdmf/utils.py:668: UserWarning: Ignoring cached namespace 'core' version 2.2.2 because version 2.7.0 is already loaded.
return func(args[0], **pargs)
[1]:
<allensdk.brain_observatory.ecephys.ecephys_session.EcephysSession at 0x14959ae90>
By default, the NWB files will be downloaded into the ecephys_cache_dir. Since nwb files are essentially just structured HDF5 files, you can use tools like HDFView or h5py to read them once they have been downloaded.
Step 2: Connecting VISL and sub-cortical area onto our V1 cells.#
To simulate synaptic stimulation from the VisL and Hippocampal cell recordings onto our V1 model, we will need to create a population of virtual cells representing the new cells and synapses. Unfortunately, the electrophysiology data doesn’t include information about network geometry, so it is up to the modeler to decide how to connect the experimental data to our network.
As we did before, we will separate node populations called ‘VISl’ and ‘Hippocampus’ and use the NetworkBuilder to create feedforward synaptic connections.
visl = NetworkBuilder('VISl')
visl.add_nodes(
N=n_visl_units,
model_type='virtual',
...
)
visl.add_edges(
source=visal.nodes(),
target=visp.nodes(ei='e'),
connection_rule=connection_rule_e2e,
dynamics_params='AMPA_ExcToExc.json',
model_template='Exp2Syn',
...
)
See the ./build_network.nwb_inputs.py for the full script that builds the SONATA network found in ./network_nwb_inputs/
Step 3: Updating the configuration file to include NWB data.#
Before we can run the simulation, we must update the SONATA configuration file so that the simulation:
Knows which .nwb files to fetch spiking data from.
Knows how to map cells (e.g., NWB units) from our experimental data to cells (e.g., SONATA nodes) in our ‘VISl’ and ‘hippocampus’ populations.
Know which time interval in the experimental data to use in our simulation.
The most straightforward way of doing this is to add the following to our configuration file (config.nwb_inputs.json) in the “inputs” section:
"inputs": {
"hippo_spikes": {
"input_type": "spikes",
"module": "ecephys_probe",
"node_set": "hippocampus",
"input_file": "./ecephys_cache_dir/session_715093703/session_715093703.nwb",
"units": {
"location": ["CA1", "CA3", "Po"]
}
"mapping": "sample",
"interval": {
"interval_name": "drifting_gratings",
"temporal_frequency": 4.0,
"orientation": 90
}
},
"visl_spikes": {
"input_type": "spikes",
"module": "ecephys_probe",
"node_set": "VISl",
"input_file": "./ecephys_cache_dir/session_715093703/session_715093703.nwb",
"mapping": "sample",
"units": {
"location": "VISl",
}
"interval": {
"interval_name": "drifting_gratings",
"temporal_frequency": 4.0,
"orientation": 90
},
}
}
When importing extracellular electrophysiology NWB files into your simulation, the input_type and module will always be set to
spikesandecephys_probe, respectively.The node_set is the subset of cells in our network used as virtual cells that generate spikes.
The input_file in the name of the nwb file(s) to use for spikes. To use data from multiple sessions, just use a list of files:
"input_file": [
"./ecephys_cache_dir/session_715093703/session_715093703.nwb",
"./ecephys_cache_dir/session_798911424/session_798911424.nwb",
"./ecephys_cache_dir/session_754829445/session_754829445.nwb"
]
The units field tells us which units from the nwb file to take their spiking data from based on specific keywords and/or unit-id. In the Neuropixels NWB files, each unit has a field called “location” to determine which region the data came from, which we can use here to tell that our model’s “hippocampus” cells use any data coming from either the CA1, CA3 or Po regions.
mapping tells how to map NWB units -> SONATA node_set. Setting the value to
samplewill result in a random mapping without replacement. You can also use optionsample_with_replacement, which is useful if your model has more nodes than units in your data. Or if you have a specific mapping from NWB unit_ids to SONATA node_ids, you can use optionunits_map(in which case units will point to a CSV file).interval tells the simulation which time interval to fetch spikes from. Inside the NWB file, there is a stimulus table that marks the stimuli at any given epoch. We use this table to get only spikes recorded in which a “drifting grating” stimulus was present with a given orientation and frequency. You can also use the following option if you know the specific time.
"interval": ["start_time_ms", "end_time_ms"]
And finally, we are ready to run our simulation.
[1]:
from bmtk.simulator import bionet
bionet.reset()
conf = bionet.Config.from_json('config.nwb_inputs.json')
conf.build_env()
net = bionet.BioNetwork.from_config(conf)
sim = bionet.BioSimulator.from_config(conf, network=net)
sim.run()
Warning: no DISPLAY environment variable.
--No graphics will be displayed.
2024-10-24 01:15:34,915 [INFO] Created log file
2024-10-24 01:15:35,070 [INFO] Building cells.
2024-10-24 01:15:41,349 [INFO] Building recurrent connections
2024-10-24 01:15:41,362 [INFO] Building virtual cell stimulations for LGN_spikes_sonata
/opt/conda/lib/python3.12/site-packages/hdmf/spec/namespace.py:535: UserWarning: Ignoring cached namespace 'hdmf-common' version 1.1.3 because version 1.8.0 is already loaded.
warn("Ignoring cached namespace '%s' version %s because version %s is already loaded."
/opt/conda/lib/python3.12/site-packages/hdmf/spec/namespace.py:535: UserWarning: Ignoring cached namespace 'core' version 2.2.2 because version 2.7.0 is already loaded.
warn("Ignoring cached namespace '%s' version %s because version %s is already loaded."
/opt/conda/lib/python3.12/site-packages/hdmf/spec/namespace.py:535: UserWarning: Ignoring cached namespace 'hdmf-common' version 1.1.3 because version 1.8.0 is already loaded.
warn("Ignoring cached namespace '%s' version %s because version %s is already loaded."
/opt/conda/lib/python3.12/site-packages/hdmf/spec/namespace.py:535: UserWarning: Ignoring cached namespace 'core' version 2.2.2 because version 2.7.0 is already loaded.
warn("Ignoring cached namespace '%s' version %s because version %s is already loaded."
2024-10-24 01:15:45,144 [INFO] Building virtual cell stimulations for VISl_spikes_nwb
2024-10-24 01:15:48,042 [INFO] Building virtual cell stimulations for Hipp_spikes_nwb
2024-10-24 01:15:49,677 [INFO] Running simulation for 2000.000 ms with the time step 0.100 ms
2024-10-24 01:15:49,678 [INFO] Starting timestep: 0 at t_sim: 0.000 ms
2024-10-24 01:15:49,679 [INFO] Block save every 5000 steps
2024-10-24 01:16:09,188 [INFO] step:5000 t_sim:500.00 ms
2024-10-24 01:16:28,971 [INFO] step:10000 t_sim:1000.00 ms
2024-10-24 01:16:48,778 [INFO] step:15000 t_sim:1500.00 ms
2024-10-24 01:17:08,752 [INFO] step:20000 t_sim:2000.00 ms
2024-10-24 01:17:08,814 [INFO] Simulation completed in 79.14 seconds
4. Example: Forcing spontaneous synaptic activity within a network#
So far, in this tutorial, we’ve focused on generating stimuli using synaptic inputs from outside our main modeled network. In other tutorials, we have used different types of input to drive a simulation, including current-clamps, voltage-clamps, and extracellular stimulation. While these can generate the kinds of stimuli we might see in experiments and living brains, they tend not to be very granular, especially when we want to study the secondary effects of activity within a network.
One option that BMTK offers for having more granular control of internal network activity is forcing certain synapses to spontaneously fire at pre-determined times. This cannot only give us more control of network dynamics, which would be much harder to achieve using current clamps or feedforward spike trains, but it also lets us isolate external activity from recurrent activity.
In BMTK, this is done by adding a new input type to the “inputs” section of the SONATA config with input_type and module called syn_activity. At the minimum, we must define the pre-synaptic cells that will spontaneously fire and a list of firing times:
"syn_activity": {
"input_type": "syn_activity",
"module": "syn_activity",
"precell_filter": {
"population": "VISp",
"ei": "e"
},
"timestamps": [500.0, 1000.0, 1500.0, 2000.0, 2500.0, 3000.0, 3500.0]
}
precell_filter determines the synapses to activate based on the presynaptic/source cell spontaneously. In this case we tell BMTK spontaneous activity to apply to synapses with a source-cell that has attributes
population==VISpandei==e. If you know exactly which cells you want to use, you can filter bynode_id:
"node_id": [0, 1, 2, 3],
timestamps is a list of timestamps, in milliseconds, to activate the neuron following startup. If you have too many timestamps to add to the JSON directly, you can also pass in a string path to a txt file where each line is a timestamp.
In the above example, all the synapses with VISp excitatory pre-synaptic connections will fire at the given timestamp. For further granular control, you can all set the postcell_filter too for filtering out synapses based on post-synaptic cells. For example, if you want spontaneous firing in exc -> inh connections (the above example would also include exc -> exc synapses:
"syn_activity": {
"input_type": "syn_activity",
"module": "syn_activity",
"precell_filter": {
"population": "VISp",
"ei": "e"
},
"postcell_filter": {
"population": "VISp",
"ei": "i"
},
"timestamps": [500.0, 1000.0, 1500.0, 2000.0, 2500.0, 3000.0, 3500.0]
}
[11]:
from bmtk.simulator import bionet
bionet.reset()
conf = bionet.Config.from_json('config.spont_syns.json')
conf.build_env()
net = bionet.BioNetwork.from_config(conf)
sim = bionet.BioSimulator.from_config(conf, network=net)
sim.run()
2024-10-24 00:05:52,474 [INFO] Created log file
Mechanisms already loaded from path: ./components/mechanisms. Aborting.
2024-10-24 00:05:52,522 [INFO] Building cells.
2024-10-24 00:06:09,970 [INFO] Building recurrent connections
2024-10-24 00:06:11,573 [INFO] Running simulation for 2000.000 ms with the time step 0.100 ms
2024-10-24 00:06:11,574 [INFO] Starting timestep: 0 at t_sim: 0.000 ms
2024-10-24 00:06:11,574 [INFO] Block save every 5000 steps
2024-10-24 00:06:49,734 [INFO] step:5000 t_sim:500.00 ms
2024-10-24 00:07:28,517 [INFO] step:10000 t_sim:1000.00 ms
2024-10-24 00:08:07,476 [INFO] step:15000 t_sim:1500.00 ms
2024-10-24 00:08:46,555 [INFO] step:20000 t_sim:2000.00 ms
2024-10-24 00:08:46,576 [INFO] Simulation completed in 2.0 minutes, 35.0 seconds
[ ]: