Current state of knowledge in the field: The brain rapidly adapts to unchanging environments, and is most excited by surprising events. A leading model to explain this phenomenon is predictive coding. Predictive coding proposes that the brain compares incoming sensory information against a prediction signal. This prediction is based on an internal model that is generated in higher-order cortex. This model reflects the brain’s assumptions about the statistics of the environment. If an incoming sensory signal matches the prediction, the two signals cancel. Expected sensory data thus are “explained away” and leave the brain unexcited. In other words, predictive coding is subtractive. The prediction signal inhibits the processing of sensory data.
Whenever the sensory signal does not match the prediction, subtraction results in a larger value, called the prediction error. This error signal initiates excitation in lower-order cortex that propagates feedforward up the cortical hierarchy (i.e., V1, RL, LM, AL, PM, and AM). Prediction errors then instigate updates to the internal model to improve future predictions. Associated prediction update signals flow back down the hierarchy. Consistent with this model, optogenetic silencing of top-down inputs from frontal to visual cortex largely eliminates prediction error signals. However, the precise circuit mechanisms that generate these signals are largely unknown. The Global/Local Oddball (GLO) project aims to close this knowledge gap. Specifically, by recording from multiple neuropixels across the visual cortical hierarchy, we will uncover what information is carried by layer 2 and 3 spikes that feed forward vs. by layer 5 and 6 spikes that feed back, using recently established analytic tools. To fully understand the involved neural mechanisms, we propose to go further: It is now possible to measure specific populations of inhibitory interneurons in tasks manipulating stimulus predictability using two-photon Calcium imaging. This technique revealed distinct computations for somatostatin (SOM+) vs. parvalbumin (PV+) interneurons in mice exposed to the same repeated (and thus predictable) stimulus. As stimuli became increasingly predictable, PV+ interneurons became less active while SOM+ interneurons became more active. Thus, the subtraction between predicted stimuli and sensory data seems to be mediated by SOM+ interneurons. This observation also implies that PV+ interneurons might be involved in the generation of prediction errors. However, this work relied on stimulus repetitions across several days, thus lacking insight into the dynamics on a more behaviorally relevant scale.
Lastly, the project aims to answer one of the most vexing paradigmatic questions of predictive coding: Significant progress in our understanding of the neural machinery underlying predictive coding stems from so-called oddball tasks. Specifically, by differentiating between so-called local (1st order) vs. global (2nd order) oddballs, researchers successfully dissociated automatic mechanisms of prediction from context-driven forms of predictive processing (Fig. 3). Cortical responses to local oddballs occur reflexively, even under deep anesthesia. Cortical responses to global oddballs require integration of stimuli across time to form complex predictions and are absent during unconsciousness. However, little is known about the neural circuitry supporting these two types of prediction errors. As we lay out below, the multi-area laminar spiking data combined with optogenetic cell type characterization (optotagging) of the Allen Institute can close this gap. Using this combination, we will specify the laminar sources, inhibitory cell types, and directions of neural signal flow (feedforward/feedback) that mediate these computations.

Environment Setup¶
⚠️Note: If running on a new environment, run this cell once and then restart the kernel⚠️
import warnings
warnings.filterwarnings('ignore')
try:
from databook_utils.dandi_utils import dandi_download_open
except:
!git clone https://github.com/AllenInstitute/openscope_databook.git
%cd openscope_databook
%pip install -e .
%cd docs/projectsimport os
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from math import floor, ceil, isclose
from PIL import ImageThe Experiment¶
As shown in the metadata table below, Openscope’s GLO Experiment has produced 15 main files on the DANDI Archive, with 5 males and 10 females. There are no wildtype mice but there are Pvalb and Sst genotypes. This table was generated from Getting Experimental Metadata from DANDI.
session_files = pd.read_csv("../../data/glo_sessions.csv")
session_filesm_count = len(session_files["sex"][session_files["sex"] == "M"])
f_count = len(session_files["sex"][session_files["sex"] == "F"])
sst_count = len(session_files[session_files["genotype"].str.count("Sst") >= 1])
pval_count = len(session_files[session_files["genotype"].str.count("Pval") >= 1])
wt_count = len(session_files[session_files["genotype"].str.count("wt/wt") >= 1])
print("Dandiset Overview:")
print(len(session_files), "files")
print(len(set(session_files["specimen_name"])), "subjects", m_count, "males,", f_count, "females")
print(sst_count, "sst,", pval_count, "pval,", wt_count, "wt")Dandiset Overview:
14 files
14 subjects 4 males, 10 females
8 sst, 6 pval, 0 wt
Downloading Ecephys File¶
dandiset_id = "000253"
dandi_filepath = "sub-637908/sub-637908_ses-1213341633_ogen.nwb"
download_loc = "."# This can sometimes take a while depending on the size of the file
io = dandi_download_open(dandiset_id, dandi_filepath, download_loc)
nwb = io.read()A newer version (0.62.4) of dandi/dandi-cli is available. You are using 0.61.2
PATH SIZE DONE DONE% CHECKSUM STATUS MESSAGE
sub-637908_ses-1213341633_ogen.nwb 2.3 GB 2.3 GB 100% - done
Summary: 2.3 GB 2.3 GB 1 done
100.00%
Downloaded file to ./sub-637908_ses-1213341633_ogen.nwb
Opening file
Showing Probe Tracks¶
The images below were rendered using the Visualizing Neuropixels Probe Locations notebook. The probes are using the Common Coordinate Framework (CCF). The experiment uses six probes labeled A-F to target various regions.
sagittal_view = Image.open("../../data/images/probes_sagittal.png")
dorsal_view = Image.open("../../data/images/probes_dorsal.png")
transverse_view = Image.open("../../data/images/probes_transverse.png")
fig, axes = plt.subplots(1,3,figsize=(20,60))
axes[0].imshow(sagittal_view)
axes[1].imshow(dorsal_view)
axes[2].imshow(transverse_view)
for ax in axes:
ax.axis("off")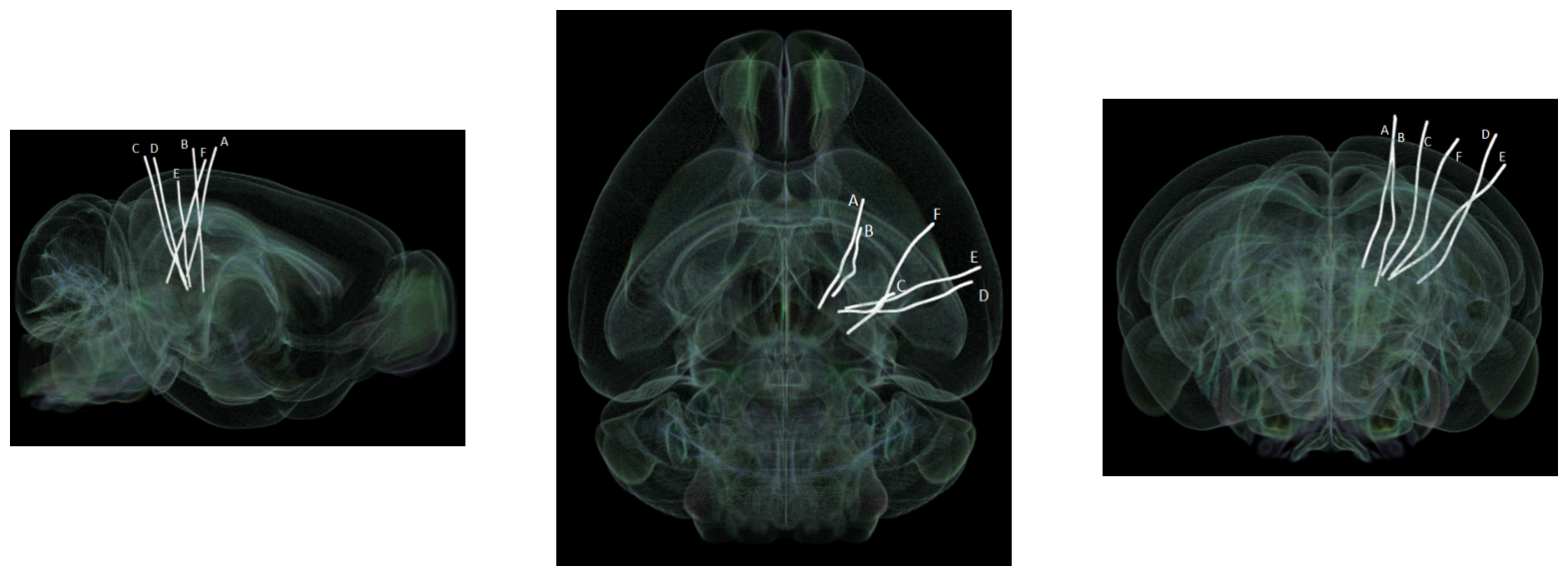
Extracting Units Spikes¶
Below, the Units table is retrieved from the file. It contains many metrics for every putative neuronal unit, printed below. For the analysis in this notebook, we are only interested in the spike_times attribute. This is an array of timestamps that a spike is measured for each unit. For more information on the various unit metrics, see Visualizing Unit Quality Metrics. From this table, the Units used in this notebook are selected if they have ‘good’ quality rather than ‘noise’, and if they belong in one of the regions of the primary visual cortex.
units = nwb.units
units[:10]# select electrodes
channel_probes = {}
electrodes = nwb.electrodes
for i in range(len(electrodes)):
channel_id = electrodes["id"][i]
location = electrodes["location"][i]
channel_probes[channel_id] = location
# function aligns location information from electrodes table with channel id from the units table
def get_unit_location(row):
return channel_probes[int(row.peak_channel_id)]
print(set(get_unit_location(row) for row in units)){'VISpm6b', 'SCig', 'ProS', 'VISam2/3', 'VISam1', 'VISrl5', 'VISpm4', 'DG-mo', 'DG-sg', 'VISrl4', 'VISpm6a', 'VISam6a', 'CA1', 'VISl5', 'TH', 'LGd-sh', 'VISp5', 'VISl4', 'SGN', 'VISl1', 'LP', 'POL', 'VISl2/3', 'VISp2/3', 'MB', 'VISpm5', 'MGd', 'DG-po', 'VISam4', 'MGm', 'VISrl2/3', 'VISrl6a', 'VISrl6b', 'VISp4', 'VISam5', 'VISp6a', 'root', 'VISl6a', 'VISrl1', 'VISp6b', 'HPF', 'CA3', 'VISpm2/3', 'SUB', 'NB', 'POST', 'VISl6b', 'VISp1', 'APN', 'PoT', 'MRN'}
### selecting units spike times
brain_regions = ["VISp6a", "VISp5", "VISp4", "VISp6b", "VISp2/3"]
# select units based if they have 'good' quality and exists in one of the specified brain_regions
units_spike_times = []
for location in brain_regions:
location_units_spike_times = []
for row in units:
if get_unit_location(row) == location and row.quality.item() == "good":
location_units_spike_times.append(row.spike_times.item())
units_spike_times += location_units_spike_times
print(len(units_spike_times))175
Session Timeline¶
To get a good idea of the order and the way stimulus is shown throughout the session, the code below generates a timeline of the various ‘epochs’ of stimulus. It can be seen that there are many repeated epochs of the gratings presentation, interspersed with intermission presentations, followed by an epoch of receptive field presentations. Note that there is an overlap of two epochs, the final gratings and the receptive field mapping presentations. This is due to a unintended stim design mistake, please be careful when analyzing data from this period.
# extract epoch times from stim table where stimulus rows have a different 'block' than following row
# returns list of epochs, where an epoch is of the form (stimulus name, stimulus block, start time, stop time)
def extract_epochs(stim_name, stim_table, epochs):
# specify a current epoch stop and start time
epoch_start = stim_table.start_time[0]
epoch_stop = stim_table.stop_time[0]
# for each row, try to extend current epoch stop_time
for i in range(len(stim_table)):
this_block = stim_table.stimulus_block[i]
# if end of table, end the current epoch
if i+1 >= len(stim_table):
epochs.append((stim_name, this_block, epoch_start, epoch_stop))
break
next_block = stim_table.stimulus_block[i+1]
# if next row is the same stim block, push back epoch_stop time
if next_block == this_block:
epoch_stop = stim_table.stop_time[i+1]
# otherwise, end the current epoch, start new epoch
else:
epochs.append((stim_name, this_block, epoch_start, epoch_stop))
epoch_start = stim_table.start_time[i+1]
epoch_stop = stim_table.stop_time[i+1]
return epochs# extract epochs from all valid stimulus tables
epochs = []
for stim_name in nwb.intervals.keys():
stim_table = nwb.intervals[stim_name]
try:
epochs = extract_epochs(stim_name, stim_table, epochs)
except:
continue
# manually add optotagging epoch since the table is stored separately
opto_stim_table = nwb.processing["optotagging"]["optogenetic_stimulation"]
opto_epoch = ("optogenetic_stimulation", 1.0, opto_stim_table.start_time[0], opto_stim_table.stop_time[-1])
epochs.append(opto_epoch)
# epochs take the form (stimulus name, stimulus block, start time, stop time)
print(len(epochs))
epochs.sort(key=lambda x: x[2])
for epoch in epochs:
print(epoch)108
('init_intermission_presentations', 0.0, 381.69655, 391.70494)
('init_grating_presentations', 1.0, 391.70494, 516.30978)
('init_intermission_presentations', 2.0, 516.81017, 526.81866)
('init_grating_presentations', 3.0, 526.81866, 651.42343)
('init_intermission_presentations', 4.0, 651.92384, 661.93225)
('init_grating_presentations', 5.0, 661.93225, 786.53705)
('init_intermission_presentations', 6.0, 787.03745, 797.0459)
('init_grating_presentations', 7.0, 797.0459, 921.6507)
('init_intermission_presentations', 8.0, 922.15112, 932.15956)
('init_grating_presentations', 9.0, 932.15956, 1056.76434)
('init_intermission_presentations', 10.0, 1057.26479, 1067.27318)
('init_grating_presentations', 11.0, 1067.27318, 1191.87797)
('init_intermission_presentations', 12.0, 1192.3784, 1202.38679)
('init_grating_presentations', 13.0, 1202.38679, 1326.99161)
('init_intermission_presentations', 14.0, 1327.49204, 1337.50046)
('init_grating_presentations', 15.0, 1337.50046, 1462.10523)
('init_intermission_presentations', 16.0, 1462.60567, 1472.61419)
('init_grating_presentations', 17.0, 1472.61419, 1597.21887)
('init_intermission_presentations', 18.0, 1597.7193, 1607.72771)
('init_grating_presentations', 19.0, 1607.72771, 1732.33249)
('init_intermission_presentations', 20.0, 1732.83289, 1742.84133)
('init_grating_presentations', 21.0, 1742.84133, 1867.44613)
('init_intermission_presentations', 22.0, 1867.94656, 1877.95497)
('init_grating_presentations', 23.0, 1877.95497, 2002.55975)
('init_intermission_presentations', 24.0, 2003.06018, 2013.06859)
('init_grating_presentations', 25.0, 2013.06859, 2139.5583)
('init_intermission_presentations', 26.0, 2140.05873, 2150.06711)
('init_grating_presentations', 27.0, 2150.06711, 2274.67192)
('init_intermission_presentations', 28.0, 2275.17236, 2285.18077)
('init_grating_presentations', 29.0, 2285.18077, 2409.78556)
('init_intermission_presentations', 30.0, 2410.28599, 2420.2944)
('init_grating_presentations', 31.0, 2420.2944, 2544.89923)
('init_intermission_presentations', 32.0, 2545.39962, 2555.40806)
('init_grating_presentations', 33.0, 2555.40806, 2680.01283)
('init_intermission_presentations', 34.0, 2680.51324, 2690.52167)
('init_grating_presentations', 35.0, 2690.52167, 2815.12647)
('init_intermission_presentations', 36.0, 2815.62691, 2825.63528)
('init_grating_presentations', 37.0, 2825.63528, 2950.24009)
('init_intermission_presentations', 38.0, 2950.74053, 2960.74894)
('init_grating_presentations', 39.0, 2960.74894, 3085.35374)
('init_intermission_presentations', 40.0, 3085.85414, 3095.86259)
('init_grating_presentations', 41.0, 3095.86259, 3120.3832)
('init_intermission_presentations', 42.0, 3120.88362, 3130.89201)
('init_grating_presentations', 43.0, 3130.89201, 3255.49683)
('init_intermission_presentations', 44.0, 3255.99729, 3266.00567)
('init_grating_presentations', 45.0, 3266.00567, 3390.61046)
('init_intermission_presentations', 46.0, 3391.1109, 3401.11938)
('init_grating_presentations', 47.0, 3401.11938, 3525.72409)
('init_intermission_presentations', 48.0, 3526.22452, 3536.23294)
('init_grating_presentations', 49.0, 3536.23294, 3660.83773)
('init_intermission_presentations', 50.0, 3661.33813, 3671.34658)
('init_grating_presentations', 51.0, 3671.34658, 3795.95137)
('init_intermission_presentations', 52.0, 3796.4518, 3806.46022)
('init_grating_presentations', 53.0, 3806.46022, 3931.06501)
('init_intermission_presentations', 54.0, 3931.56544, 3941.57382)
('init_grating_presentations', 55.0, 3941.57382, 4066.17863)
('init_intermission_presentations', 56.0, 4066.67907, 4076.68749)
('init_grating_presentations', 57.0, 4076.68749, 4201.29228)
('init_intermission_presentations', 58.0, 4201.79269, 4211.80112)
('init_grating_presentations', 59.0, 4211.80112, 4336.40592)
('init_intermission_presentations', 60.0, 4336.90635, 4346.91476)
('init_grating_presentations', 61.0, 4346.91476, 4471.51956)
('init_intermission_presentations', 62.0, 4472.01996, 4482.0284)
('init_grating_presentations', 63.0, 4482.0284, 4606.6332)
('init_intermission_presentations', 64.0, 4607.13359, 4617.14205)
('init_grating_presentations', 65.0, 4617.14205, 4741.74684)
('init_intermission_presentations', 66.0, 4742.24727, 4752.25568)
('init_grating_presentations', 67.0, 4752.25568, 4761.7637)
('init_intermission_presentations', 68.0, 4762.2641, 4772.27252)
('init_grating_presentations', 69.0, 4772.27252, 4896.87731)
('init_intermission_presentations', 70.0, 4897.37774, 4907.38619)
('init_grating_presentations', 71.0, 4907.38619, 5031.99096)
('init_intermission_presentations', 72.0, 5032.49138, 5042.4998)
('init_grating_presentations', 73.0, 5042.4998, 5167.10456)
('init_intermission_presentations', 74.0, 5167.60502, 5177.61349)
('init_grating_presentations', 75.0, 5177.61349, 5302.21821)
('init_intermission_presentations', 76.0, 5302.71863, 5312.72708)
('init_grating_presentations', 77.0, 5312.72708, 5437.33184)
('init_intermission_presentations', 78.0, 5437.83228, 5447.84072)
('init_grating_presentations', 79.0, 5447.84072, 5572.44554)
('init_intermission_presentations', 80.0, 5572.94596, 5582.95439)
('init_grating_presentations', 81.0, 5582.95439, 5707.55911)
('init_intermission_presentations', 82.0, 5708.0596, 5718.06809)
('init_grating_presentations', 83.0, 5718.06809, 5842.67278)
('init_intermission_presentations', 84.0, 5843.17322, 5853.18163)
('init_grating_presentations', 85.0, 5853.18163, 5857.6854)
('init_intermission_presentations', 86.0, 5858.18584, 5868.19423)
('init_grating_presentations', 87.0, 5868.19423, 5992.79906)
('init_intermission_presentations', 88.0, 5993.29951, 6003.30787)
('init_grating_presentations', 89.0, 6003.30787, 6127.91269)
('init_intermission_presentations', 90.0, 6128.41312, 6138.42155)
('init_grating_presentations', 91.0, 6138.42155, 6263.02633)
('init_intermission_presentations', 92.0, 6263.52676, 6273.53515)
('init_grating_presentations', 93.0, 6273.53515, 6398.13998)
('init_intermission_presentations', 94.0, 6398.64041, 6408.64884)
('init_grating_presentations', 95.0, 6408.64884, 6533.25366)
('init_intermission_presentations', 96.0, 6533.75403, 6543.76247)
('init_grating_presentations', 97.0, 6543.76247, 6668.36726)
('init_intermission_presentations', 98.0, 6668.86769, 6678.87611)
('init_grating_presentations', 99.0, 6678.87611, 6803.48092)
('create_receptive_field_mapping_presentations', 100.0, 6794.97378, 7281.38293)
('init_intermission_presentations', 101.0, 6803.98131, 6813.98979)
('init_grating_presentations', 102.0, 6813.98979, 6938.59456)
('init_intermission_presentations', 103.0, 6939.09498, 6949.1034)
('init_grating_presentations', 104.0, 6949.1034, 7073.70817)
('init_intermission_presentations', 105.0, 7074.20862, 7084.21703)
('init_grating_presentations', 106.0, 7084.21703, 7158.77976)
('optogenetic_stimulation', 1.0, 7353.87906, 8219.60458)
time_start = floor(min([epoch[2] for epoch in epochs]))
time_end = ceil(max([epoch[3] for epoch in epochs]))
all_units_spike_times = np.concatenate(units_spike_times).ravel()
print(time_start, time_end)
# make histogram of unit spikes per second over specified timeframe
time_bin_edges = np.linspace(time_start, time_end, (time_end-time_start))
hist, bins = np.histogram(all_units_spike_times, bins=time_bin_edges)381 8220
# generate plot of spike histogram with colored epoch intervals and legend
fig, ax = plt.subplots(figsize=(15,5))
# assign unique color to each stimulus name
stim_names = list({epoch[0] for epoch in epochs})
colors = plt.cm.rainbow(np.linspace(0,1,len(stim_names)))
stim_color_map = {stim_names[i]:colors[i] for i in range(len(stim_names))}
epoch_key = {}
height = max(hist)
# draw colored rectangles for each epoch
for epoch in epochs:
stim_name, stim_block, epoch_start, epoch_end = epoch
color = stim_color_map[stim_name]
rec = ax.add_patch(mpl.patches.Rectangle((epoch_start, 0), epoch_end-epoch_start, height, alpha=0.2, facecolor=color))
epoch_key[stim_name] = rec
ax.set_xlim(time_start, time_end)
ax.set_ylim(-0.1, height+0.1)
ax.set_xlabel("time (s)")
ax.set_ylabel("# spikes")
ax.set_title("All Unit Spikes Per Second Throughout Epochs")
fig.legend(epoch_key.values(), epoch_key.keys(), loc="lower right", bbox_to_anchor=(1.18, 0.25))
ax.plot(bins[:-1], hist)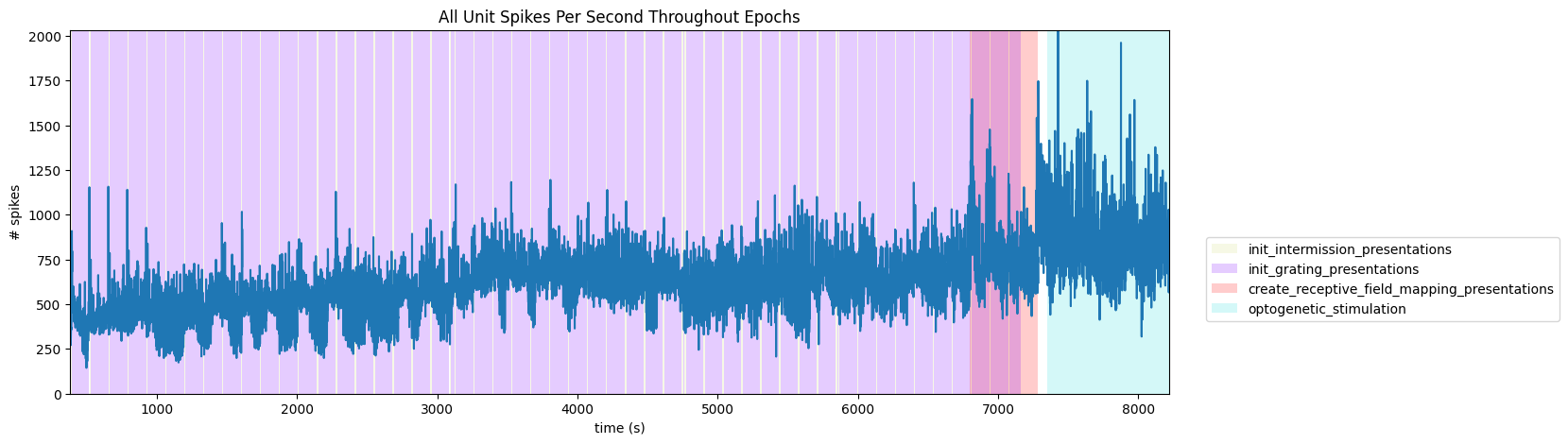
Extracting Stimulus Times¶
nwb.intervals.keys()dict_keys(['create_receptive_field_mapping_presentations', 'init_grating_presentations', 'init_intermission_presentations', 'invalid_times', 'spontaneous_presentations'])stim_table = nwb.intervals["init_grating_presentations"]
print(np.mean(np.diff(stim_table.start_time)))
print({elem for elem in stim_table.orientation if not np.isnan(elem)})1.0845607324891808
{45.0, 135.0}
stim_table[:10]# select times where there is a local oddball
lo_stim_select = lambda prev_row, row, next_row: prev_row.orientation.item() == 135.0 and row.orientation.item() == 45.0 and np.isnan(next_row.orientation.item())
lo_stim_times = [float(stim_table[i].start_time) for i in range(1,len(stim_table)-1) if lo_stim_select(stim_table[i-1], stim_table[i], stim_table[i+1])]
print(len(lo_stim_times))
# select times where there is a global oddball
go_stim_select = lambda prev_row, row, next_row: prev_row.orientation.item() == 135.0 and row.orientation.item() == 135.0 and np.isnan(next_row.orientation.item())
go_stim_times = [float(stim_table[i].start_time) for i in range(1,len(stim_table)-1) if go_stim_select(stim_table[i-1], stim_table[i], stim_table[i+1])]
print(len(go_stim_times))675
322
Generating Spike Matrix¶
# bin size for counting spikes
time_resolution = 0.005
# start and end times (relative to the stimulus at 0 seconds) that we want to examine and align spikes to
window_start_time = -0.25
window_end_time = 0.5def get_spike_matrix(stim_times, units_spike_times, bin_edges):
time_resolution = np.mean(np.diff(bin_edges))
# 3D spike matrix to be populated with spike counts
spike_matrix = np.zeros((len(units_spike_times), len(stim_times), len(bin_edges)-1))
# populate 3D spike matrix for each unit for each stimulus trial by counting spikes into bins
for unit_idx in range(len(units_spike_times)):
spike_times = units_spike_times[unit_idx]
for stim_idx, stim_time in enumerate(stim_times):
# get spike times that fall within the bin's time range relative to the stim time
first_bin_time = stim_time + bin_edges[0]
last_bin_time = stim_time + bin_edges[-1]
first_spike_in_range, last_spike_in_range = np.searchsorted(spike_times, [first_bin_time, last_bin_time])
spike_times_in_range = spike_times[first_spike_in_range:last_spike_in_range]
# convert spike times into relative time bin indices
bin_indices = ((spike_times_in_range - (first_bin_time)) / time_resolution).astype(int)
# mark that there is a spike at these bin times for this unit on this stim trial
for bin_idx in bin_indices:
spike_matrix[unit_idx, stim_idx, bin_idx] += 1
return spike_matrix# time bins used
n_bins = int((window_end_time - window_start_time) / time_resolution)
bin_edges = np.linspace(window_start_time, window_end_time, n_bins, endpoint=True)
# calculate baseline and stimulus interval indices for use later
stimulus_onset_idx = int(-bin_edges[0] / time_resolution)
lo_spike_matrix = get_spike_matrix(lo_stim_times, units_spike_times, bin_edges)
go_spike_matrix = get_spike_matrix(go_stim_times, units_spike_times, bin_edges)
print(lo_spike_matrix.shape)
print(go_spike_matrix.shape)(175, 675, 149)
(175, 322, 149)
Showing Response Windows¶
After generating spike matrices, we can view the PSTHs for each unit.
def show_response(ax, window, window_start_time, window_end_time, aspect="auto", vmin=None, vmax=None, yticklabels=[], skipticks=1, xlabel="Time (s)", ylabel="ROI", cbar=True, cbar_label=None):
if len(window) == 0:
print("Input data has length 0; Nothing to display")
return
img = ax.imshow(window, aspect=aspect, extent=[window_start_time, window_end_time, 0, len(window)], interpolation="none", vmin=vmin, vmax=vmax)
if cbar:
ax.colorbar(img, shrink=0.5, label=cbar_label)
ax.plot([0,0],[0, len(window)], ":", color="white", linewidth=1.0)
if len(yticklabels) != 0:
ax.set_yticks(range(len(yticklabels)))
ax.set_yticklabels(yticklabels, fontsize=8)
n_ticks = len(yticklabels[::skipticks])
ax.yaxis.set_major_locator(plt.MaxNLocator(n_ticks))
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)def show_many_responses(windows, rows, cols, window_idxs=None, title=None, subplot_title="", xlabel=None, ylabel=None, cbar_label=None, vmin=0, vmax=2):
if window_idxs is None:
window_idxs = range(len(windows))
windows = windows[window_idxs]
# handle case with no input data
if len(windows) == 0:
print("Input data has length 0; Nothing to display")
return
# handle cases when there aren't enough windows for number of rows
if len(windows) < rows*cols:
rows = (len(windows) // cols) + 1
fig, axes = plt.subplots(rows, cols, figsize=(2*cols, 3*rows), layout="constrained")
# handle case when there's only one row
if len(axes.shape) == 1:
axes = axes.reshape((1, axes.shape[0]))
for i in range(rows*cols):
ax_row = int(i // cols)
ax_col = i % cols
ax = axes[ax_row][ax_col]
if i > len(windows)-1:
ax.set_visible(False)
continue
window = windows[i]
show_response(ax, window, window_start_time, window_end_time, xlabel=xlabel, ylabel=ylabel, cbar=False, vmin=vmin, vmax=vmax)
ax.set_title(f"{subplot_title} {window_idxs[i]}")
if ax_row != rows-1:
ax.get_xaxis().set_visible(False)
if ax_col != 0:
ax.get_yaxis().set_visible(False)
fig.suptitle(title)
norm = mpl.colors.Normalize(vmin=vmin, vmax=vmax)
colorbar = fig.colorbar(mpl.cm.ScalarMappable(norm=norm), ax=axes, shrink=2/cols, label=cbar_label)
show_many_responses(lo_spike_matrix, 5, 10)
show_many_responses(go_spike_matrix, 5, 10)
Selecting Responsive Cells¶
As discussed in Statistically Testing 2P Responses to Stimulus, the criteria used to select for responsive cells can have a significant impact. Here, the simple criterion is to select units whose post-stimulus z-scores are greater than 1 or less than -1.
def select_cells(spike_matrix, stimulus_onset_idx):
baseline_means = np.mean(spike_matrix[:,:,:stimulus_onset_idx], axis=2)
mean_baseline_means = np.mean(baseline_means, axis=1)
std_baseline_means = np.std(baseline_means, axis=1)
response_means = np.mean(spike_matrix[:,:,stimulus_onset_idx:], axis=2)
mean_response_means = np.mean(response_means, axis=1)
unit_z_scores = (mean_response_means - mean_baseline_means) / std_baseline_means
return np.where(np.logical_or(unit_z_scores > 1, unit_z_scores < -1))[0]lo_selected_idxs = select_cells(lo_spike_matrix, stimulus_onset_idx)
show_many_responses(lo_spike_matrix[lo_selected_idxs], 5, 10)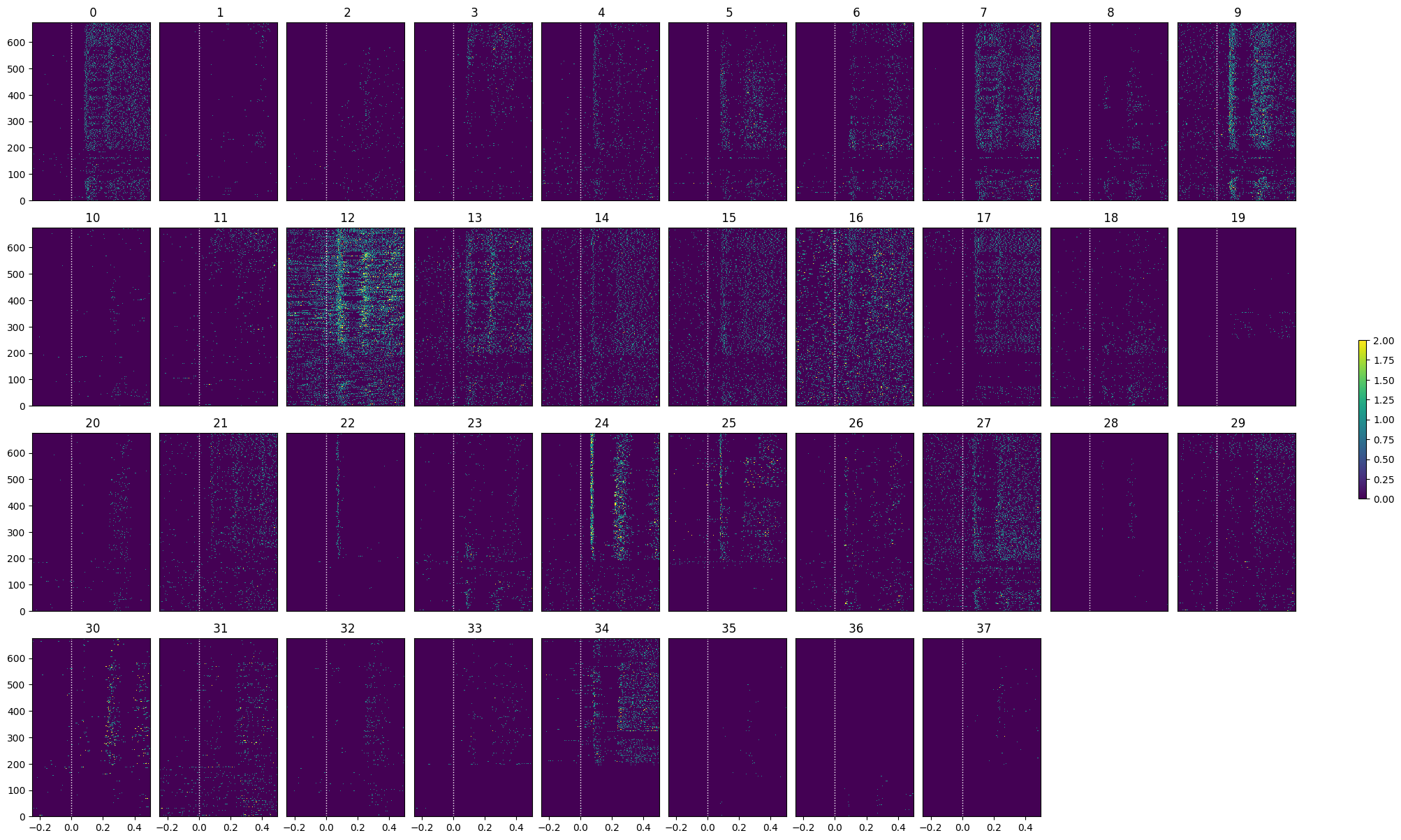
go_selected_idxs = select_cells(go_spike_matrix, stimulus_onset_idx)
show_many_responses(go_spike_matrix[go_selected_idxs], 5, 10)
Optotagging¶
As mentioned earlier, the final epoch of the sessions is optotagging. The principles behind the optotagging are discussed in the Identifying Optotagged Units notebook.
opto_stim_table = nwb.processing["optotagging"]["optogenetic_stimulation"]
opto_stim_table[:20]opto_stim_times = [float(row.start_time) for row in opto_stim_table if isclose(float(row.duration), 1.0)]
len(opto_stim_times)
len(units_spike_times)175# bin size for counting spikes
time_resolution = 0.005
# start and end times (relative to the stimulus at 0 seconds) that we want to examine and align spikes to
window_start_time = -0.25
window_end_time = 0.5# time bins used
n_bins = int((window_end_time - window_start_time) / time_resolution)
bin_edges = np.linspace(window_start_time, window_end_time, n_bins, endpoint=True)
# calculate baseline and stimulus interval indices for use later
stimulus_onset_idx = int(-bin_edges[0] / time_resolution)
opto_spike_matrix = get_spike_matrix(opto_stim_times, units_spike_times, bin_edges)
print(opto_spike_matrix.shape)(175, 450, 149)
show_many_responses(opto_spike_matrix, 5, 10)
opto_selected_idxs = select_cells(opto_spike_matrix, stimulus_onset_idx)
show_many_responses(opto_spike_matrix[opto_selected_idxs], 5, 10)