9. Multi-Resolution Support¶
9.1 Resolution Level Structure¶
Each pyramid level lives under a bare-integer sub-group of the store
root: 0/ is full resolution, 1/, 2/, … are progressively
coarser. Per-level metadata (zarr.json["zarr_vectors_level"])
carries the level index, vertex count, source level
(parent_level), bin grid, and an optional chunk_shape override
(v0.7).
Levels are independent Zarr groups — a reader that only needs the coarsest level fetches only that level’s blobs. Levels do not duplicate root metadata (axes, bounds, CRS, conventions); those are all root-only.
9.2 Downsampling Strategies¶
Below is a toy example to help you visualize and conceptualize what a multi-scale coarsening of a graph with edges would look like
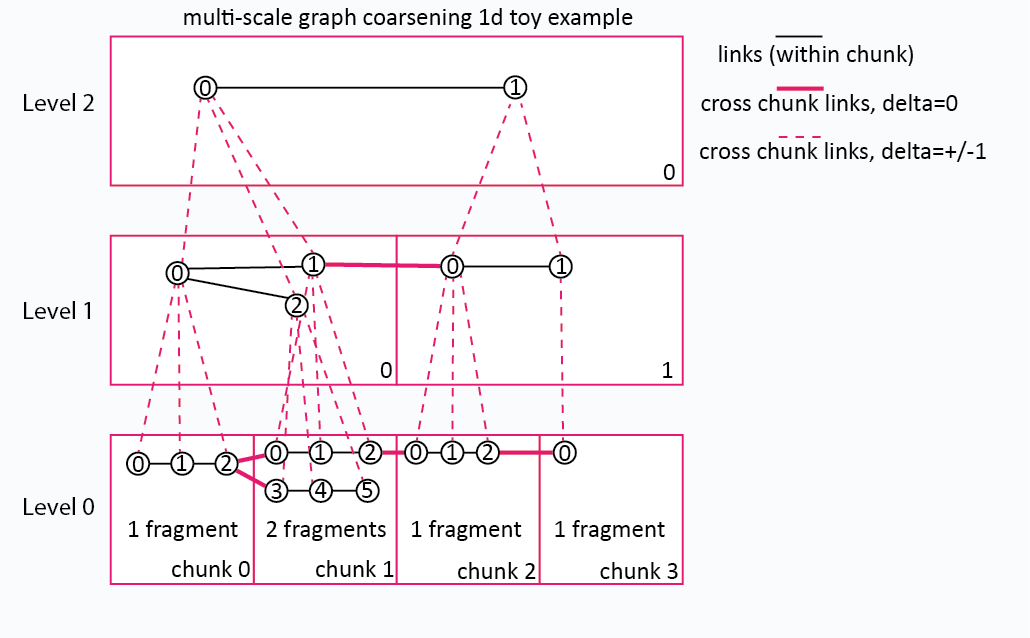
Per-object coarsening (coarsening_method = "per_object")¶
The default. Each surviving object’s vertices are aggregated into metavertices on a coarser bin grid:
Each level-0 fragment is mapped to a coarse-level bin via
bin_ratio(per-axis integer fold-change of the bin shape).Per object, per coarse bin, the contributing level-0 vertices reduce to a single metavertex (centroid, mean, mode — depending on the writer). Per-vertex attributes follow the same reduction.
The coarse-level fragment for that object then carries the metavertex rows; the fragment’s parent edges live in
links/+1/<chunk>(when emitted — see §9.6).
Per-object coarsening preserves object identity across levels: an
object dropped at a coarser level retains its OID slot, and its
manifest is empty. Levels emitted this way set
preserves_object_ids = true and carry inherited_num_objects (the
OID-space size copied from the parent level).
The object_sparsity field records the fraction of source-level
objects that survived to this level (1.0 = none dropped).
Manual or none (coarsening_method = "manual" | "none")¶
"manual" indicates the level was authored by a caller-supplied
coarsening function (no schema constraint beyond the standard level
invariants). "none" is used for level 0 itself.
Other geometries¶
Meshes: typically use edge-collapse decimation; the resulting vertex / face arrays are written under coarsening_method =
"manual".Skeletons: path simplification (Douglas-Peucker) keeps branch points and reduces straight-segment density.
Streamlines / polylines: point reduction along paths.
9.3 Spatial Chunk Scaling (v0.7)¶
RootMetadata.chunk_shape defines the finest (level-0) chunk
grid. Each pyramid level may override the chunk shape via
zarr_vectors_level.chunk_shape. The override is constrained:
Nested grids: per axis, level
chunk_shape_axismust be a positive integer multipler_iof rootchunk_shape_axis. A level-N chunk’s parent in the level-(N-1) grid is a single chunk; the inverse cover is∏ r_ilevel-(N-1) chunks.Bin compatibility: per axis, level
chunk_shape_axismust be an integer multiple of levelbin_shape_axis(bins still tile chunks cleanly at every level).
chunk_scale_factor(root_meta, level_meta) exposes the tuple
(r_0, …, r_{ndim-1}); cross-level chunk-coord translation is
integer division:
coord_level_N = coord_level_0 // (r_0_cumulative, …)
Writers that don’t grow chunks per level leave the override unset;
those levels inherit root chunk_shape exactly. The
build_pyramid(..., chunk_scale_factors=[r1, r2, ...]) entry point
in zarr_vectors.multiresolution emits the per-level metadata in one
pass.
This plays the same role for vector pyramids that voxel-size scaling plays for OME-Zarr image pyramids: coarser levels can amortise per-chunk overhead by holding larger physical regions, while readers keep using integer arithmetic to walk between levels.
9.4 Level-of-Detail Selection¶
Readers choose a level by:
Vertex budget: pick the coarsest level whose
vertex_countfits the budget for the visible region.Pixel size: pick the level whose per-vertex physical spacing approaches one screen pixel — for a per-object pyramid, level N’s metavertex spacing is
bin_shape_N.Manual: pick a specific
levelindex.
reduction_factor (root metadata) lets a writer indicate that levels
should differ by ≥ that factor in vertex count, so an LOD picker can
assume each adjacent pair is meaningfully coarser.
9.5 Consistency Across Levels¶
The format keeps these invariants:
bounds,crs,geometry_types, and conventions are root-only and shared by every level.bin_shapeand (optionally)chunk_shapeare per-level overrides; level 0 inherits both from root.object_idspace is preserved by per-object pyramids; dropped objects retain empty manifest rows.Cross-level edges, when emitted, live in
links/<delta>/<chunk>(intra-chunk) andcross_chunk_links/<delta>/data(cross-chunk), with endpoint 0 at the owning level and endpoint k > 0 at levelowning + delta.
9.6 Multiscale Link Arrays — Optional¶
Cross-pyramid-level links — links/<delta>/<chunk> and
cross_chunk_links/<delta>/data for delta ≠ 0 — are an optional
feature, not a baseline schema requirement. Whether a store
includes them is a writer-side choice driven by the consumer use
case:
Turn them on when you want any of:
Fragment-level LOD selection — a viewer that swaps a fine-level fragment for its coarse parent on zoom-out needs the mapping.
Provenance tracing — given a coarse metavertex, which level-0 vertices fed into it?
Drillable pyramid traversal — the user clicks a coarse-level object and the renderer streams in the corresponding fine-level fragments.
Sparsified or down-sampled coarse levels where each coarse object is still recognizably the same object as a fine-level one, and the renderer wants to follow that identity across levels.
Skip them when your pyramid’s coarse levels are independent
simplifications — fewer points to draw at low zoom, no need to relate
back to the fine-level vertices. These pyramids set
cross_level_storage = "none", never emit <delta> ≠ 0 arrays, and
pay no storage cost. The trade-off is hard: those stores cannot be
“drilled” — readers must treat each level as its own representation.
The <delta> sub-folder layout¶
Every link-bearing array path carries a per-pyramid-level-delta segment between the array name and the chunk key:
links/<delta>/<chunk>
cross_chunk_links/<delta>/data
link_attributes/<name>/<delta>/<chunk>
cross_chunk_link_attributes/<name>/<delta>/data
<delta> = 0 is mandatory whenever the geometry has explicit links
at all (it’s where same-level links live). <delta> ≠ 0 is the
optional cross-pyramid-level capability.
Stores that emit any <delta> ≠ 0 array advertise
CAP_MULTISCALE_LINKS in format_capabilities. A reader missing
that token must treat coarser levels as independent simplifications.
Storage knobs¶
Two root-metadata fields control emission:
cross_level_storage∈{"none", "implicit", "explicit"}"none"— skip cross-pyramid-level link arrays entirely. Lowest cost; pyramid is non-drillable."implicit"— emit only+N(at the finer level). Readers can map fine → coarse; the inverse requires an explicit inversion pass at read time. Halves the storage cost vs"explicit"."explicit"(default) — emit both+N(at the finer level) and-N(at the coarser level). Both directions queryable at read time.
cross_level_depth— max|delta|materialized. Defaults to1(just ±1 between adjacent level pairs).N > 1materializes ±1, ±2, …, ±N by composing the per-step mappings during pyramid build.0disables;-1walks all available adjacent level pairs.
Reading the pyramid via multiscale links¶
Given a fine-level fragment in chunk c at level L, the parent
metavertex at level L+1 is reached by:
Read the level-L
links/+1/<c>payload (a flat sequence oflink_width = 1records keyed by source fragment).Each record carries an endpoint
(c', v')at level L+1 — the parent metavertex’s chunk and row index in that chunk’svertices/<c'>(which may be a different chunk under v0.7 chunk-shape growth:c' = c // r).Inverse (
-1) traversal works analogously whencross_level_storage = "explicit".
For deeper traversal, compose step-by-step or read a pre-materialized
deeper delta (+2, +3, …) up to cross_level_depth.
Interaction with v0.7 chunk-scale growth¶
When chunk_scale_factor > 1, a level-N chunk physically covers ∏ r_i level-(N-1) chunks. The natural source and target chunk
coordinates for a cross-level link record are then different —
the format already supports this because each endpoint carries its
own chunk-coord tuple inline. Per-axis translation between the two
chunk coordinates is integer division by the cumulative scale
factor.